인터넷에 올려진 파일을 R을 이용해서 다운로드 하기
R · 케이플러스 한성탁 ·download.file()
인터넷에서 파일을 다운로드 받을 경우 대부분 인터넷 익스플로러나 크롬 등의 인터넷 브라우저를 통해 다운로드를 받거나 전송 프로그램 등을 쓰게 되지만, R을 통해서 download.file() 함수를 이용해 파일 다운로드를 받을 수도 있습니다.
윈도우(windows 10 64bit) 운영체제 기준으로 예를 하나 들어보겠습니다.
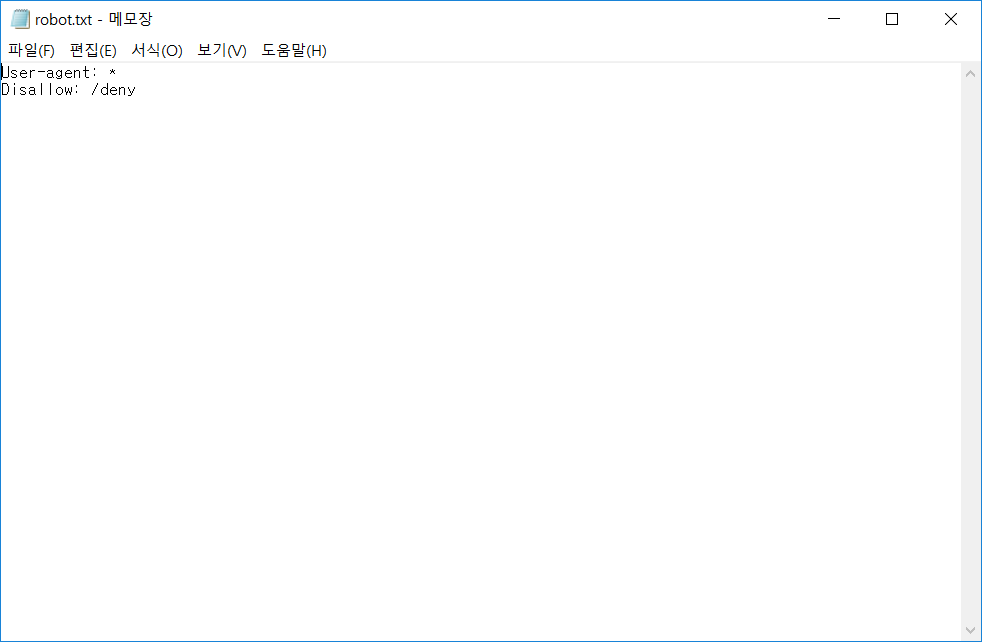
https://httpbin.org/robots.txt 파일을 다운받아서 저장해보겠습니다.
download.file(url = "https://httpbin.org/robots.txt", destfile = "robot.txt")
윈도우 기준 R의 Working directory는 내 문서이므로 “내 문서/robots.txt” 경로에 저장이 됩니다.
열어보면 잘 다운로드가 되었습니다.
이번엔 jpeg 이미지 파일을 다운로드 받아보겠습니다.
download.file(url = "https://httpbin.org/image/jpeg", destfile = "fox.jpeg")
내 문서 폴더에 가서 확인해보면 파일이 손상되었다고 합니다. 이는 jpeg 파일은 텍스트 파일과 다르게 이진 파일(Binary file)이기 때문입니다. 따라서 옵션을 추가해줘야 합니다.
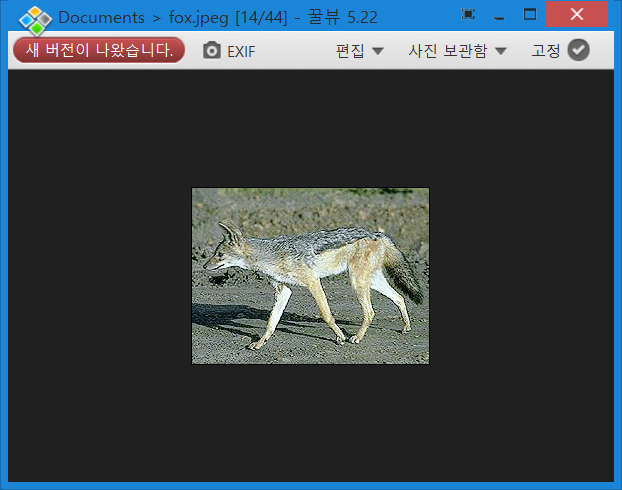
download.file(url = "https://httpbin.org/image/jpeg", destfile = "fox.jpeg", mode="wb")
이제 다운로드가 잘 되어 여우 사진을 확인할 수 있습니다.
dir.create()
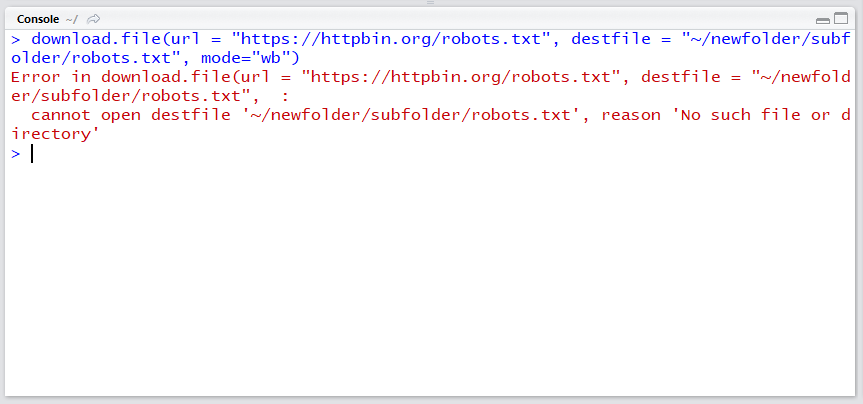
존재하지 않는 폴더에 다운로드를 시도하면 오류가 납니다.
download.file(url = "https://httpbin.org/robots.txt", destfile = "~/newfolder/subfolder/robots.txt", mode="wb")
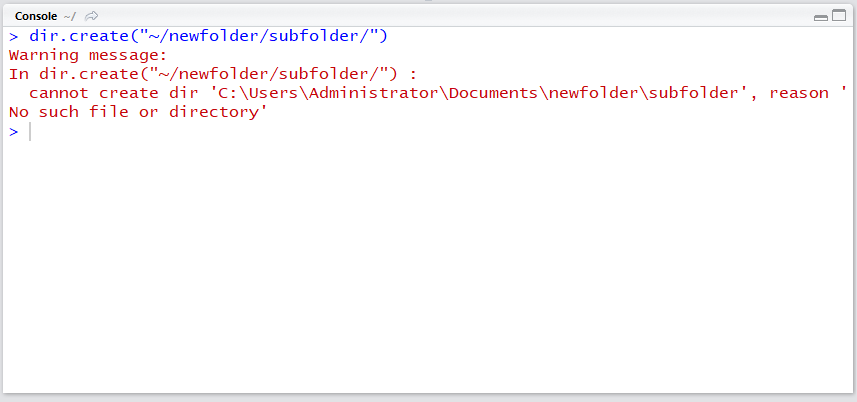
미리 dir.create() 함수를 사용해서 폴더를 만들어주면 에러가 발생하지 않습니다. 그런데 dir.create()는 폴더를 한번에 하나 씩 생성하므로 아래 처럼 사용하면 다시 에러가 납니다.
dir.create("~/newfolder/subfolder/")
그래서 단계 별로 폴더를 1개씩 만들어주던가 recursive=TRUE로 지정해 주어야 합니다. 그 후에 다운로드를 시도하면 잘 실행 됩니다.
dir.create("~/newfolder/")
dir.create("~/newfolder/subfolder/")
#or
dir.create("~/newfolder/subfolder/", recursive = T)
download.file(url = "https://httpbin.org/robots.txt", destfile = "~/newfolder/subfolder/robots.txt", mode="wb")
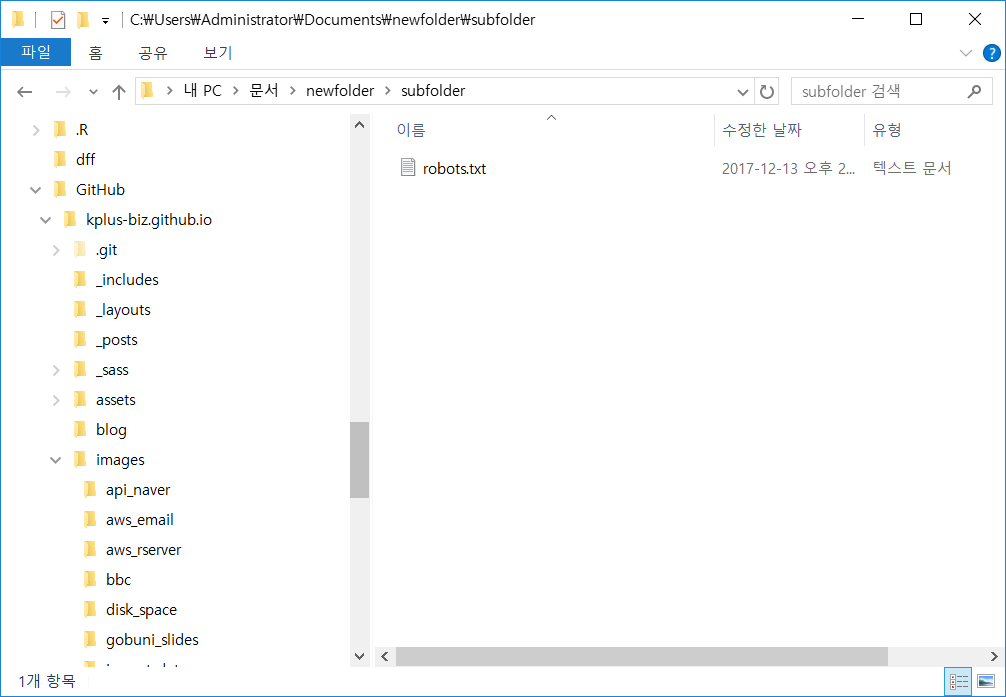
이미 폴더가 존재하는데 dir.create() 함수로 다시 폴더를 만드려고 시도할 경우 경고 메시지가 나옵니다. 이런 것을 방지하려면 if문과 dir.exist() 함수를 통해 미리 폴더가 있는지를 확인하고 dir.create() 를 사용할 수 있겠으나 이미 존재하는 폴더에 dir.create() 를 시도한다고 하여 폴더 안의 파일에 영향이 가지는 않기 때문에 그냥 경고를 무시하셔도 무방합니다.
이진 파일
이제 다운받으려고 하는 파일이 이진 파일인지 아닌지 판단하는 기준을 알아보겠습니다. 간단하게 파일이 메모장으로 열리는지를 기준으로 생각하시면 됩니다. 메모장으로 열리는 *.txt 파일과 *.R *.py *.html *.csv 등의 서식이 없는 문서파일, 프로그래밍 언어 소스 파일등은 이진파일이 아니고, .avi, .jpg, .pdf, .hwp 등의 메모장으로 열리지 않는 파일이나 사진 파일, 동영상 파일 등은 이진파일입니다.
- 이진파일이 아닌 경우 mode=”w”
- 이진파일일 경우 mode=”wb”
- 다운로드 받으려는 파일이 이미 존재할 시 파일 내용을 이어 붙이려면 mode=”a” 또는 mode=”ab”
으로 사용하면 됩니다. 또한 파일 다운로드 시 진행 바가 나오지 않게 하려면 quiet=TRUE를 추가하십시오.
또한 Method 항목에서 다운로드 받는 방법을 정하는데, 윈도우는 “wininet”, 우분투 리눅스의 경우 “libcurl”이 기본값으로 설정되어 있습니다. 이 값은 따로 건드릴 필요는 없습니다.
ID, 비밀번호 등의 접근 권한이 필요한 파일이나 요청을 받으면 내부적으로 처리를 해서 다운로드 링크를 반환하는 홈페이지 같은 경우 download.file()를 통한 다운로드 난이도가 대폭 증가하므로 이 포스트에서 다루지 않겠습니다. 이러한 파일들은 양이 많지 않은 경우 수작업으로 받는 게 가장 좋지만, 자동화가 꼭 필요한 경우 아이디나 비밀번호 정보를 포함하는 접근이나 브라우저 자동화 등이 필요합니다.