R에서 네이버 검색 API 사용하기
예제 · 케이플러스 한성탁 ·- 네이버 API
네이버에서는 api를 통해 마우스 클릭 등의 행동을 통하지 않고서도 브라우저의 주소창이나 GET 프로토콜을 이용하여 네이버의 기능을 사용할 수 있습니다.
예를 들어 ‘안드로이드’에 대한 검색 결과를 알고 싶을 때 https://www.naver.com/ 에 접속하여 주소창에 ‘안드로이드’를 치고 엔터를 눌러 검색을 하는 행동을,
https://openapi.naver.com/v1/search/webkr.xml?query=%ec%95%88%eb%93%9c%eb%a1%9c%ec%9d%b4%eb%93%9c
에 접속하는 것으로 대신할 수 있는 것입니다. (위의 링크의 경우 아직 권한이 없어서 에러가 발생합니다)
이때 query=”검색어” 부분에서 검색어가 한글일 경우, 문자열을 URL 인코딩을 통해 api에서 인식하는 인코딩 형식으로 변환해야 하는 경우가 있습니다. ‘안드로이드’을 URL 인코딩하면 %ec%95%88%eb%93%9c%eb%a1%9c%ec%9d%b4%eb%93%9c입니다.
- 네이버 API 생성하기
이제 네이버 아이디가 있다고 가정하고 api를 사용하기 위한 앱을 생성해보겠습니다.
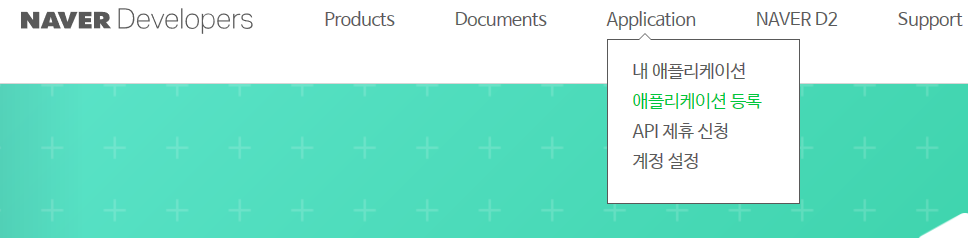
네이버 개발자 페이지(링크)에 들어갑니다. 네이버에 로그인 한 후 Application → 애플리케이션 등록을 클릭합니다.
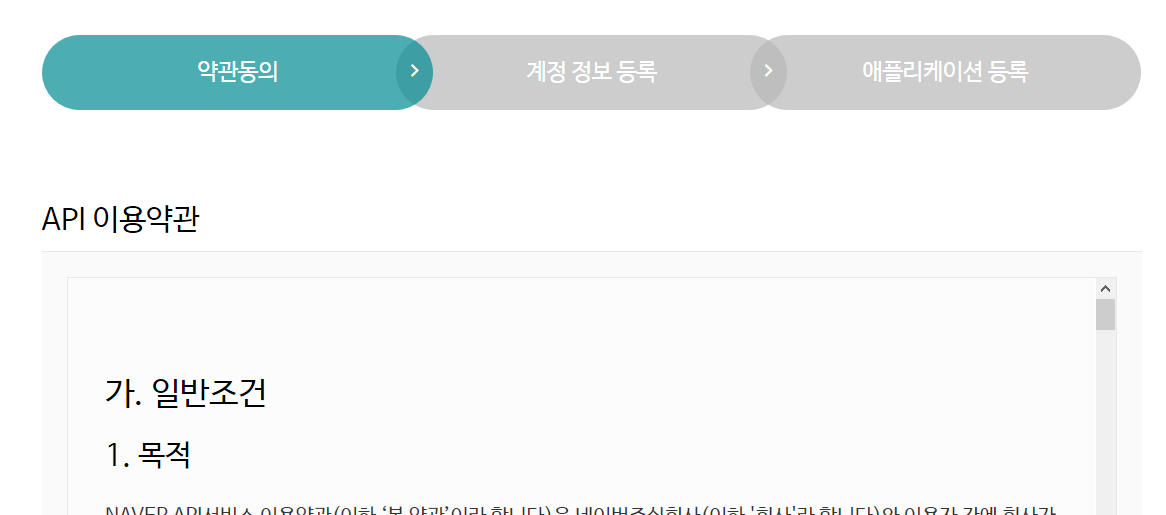
API 이용 약관에 동의한 후 다음으로 넘어갑니다. 이용자의 의무와 네이버의 면책사항 등이 있습니다. 이용 약관은 꼭 읽어보시기를 추천합니다.
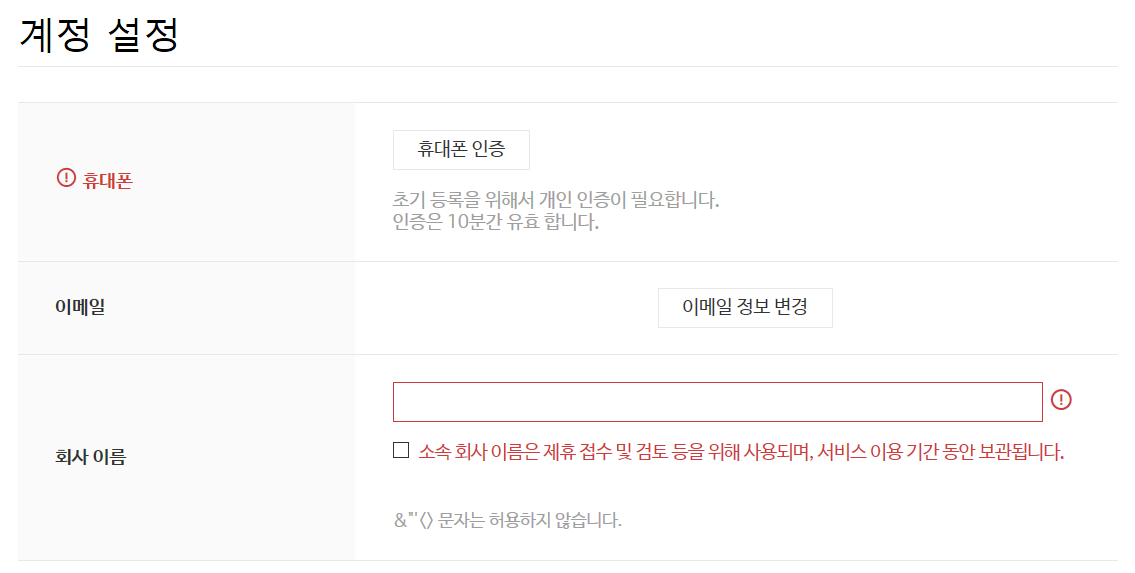
휴대폰 인증 및 이메일, 회사 이름 등을 입력합니다. 학생의 경우 학교 이름등을 넣으면 될 것 같습니다.
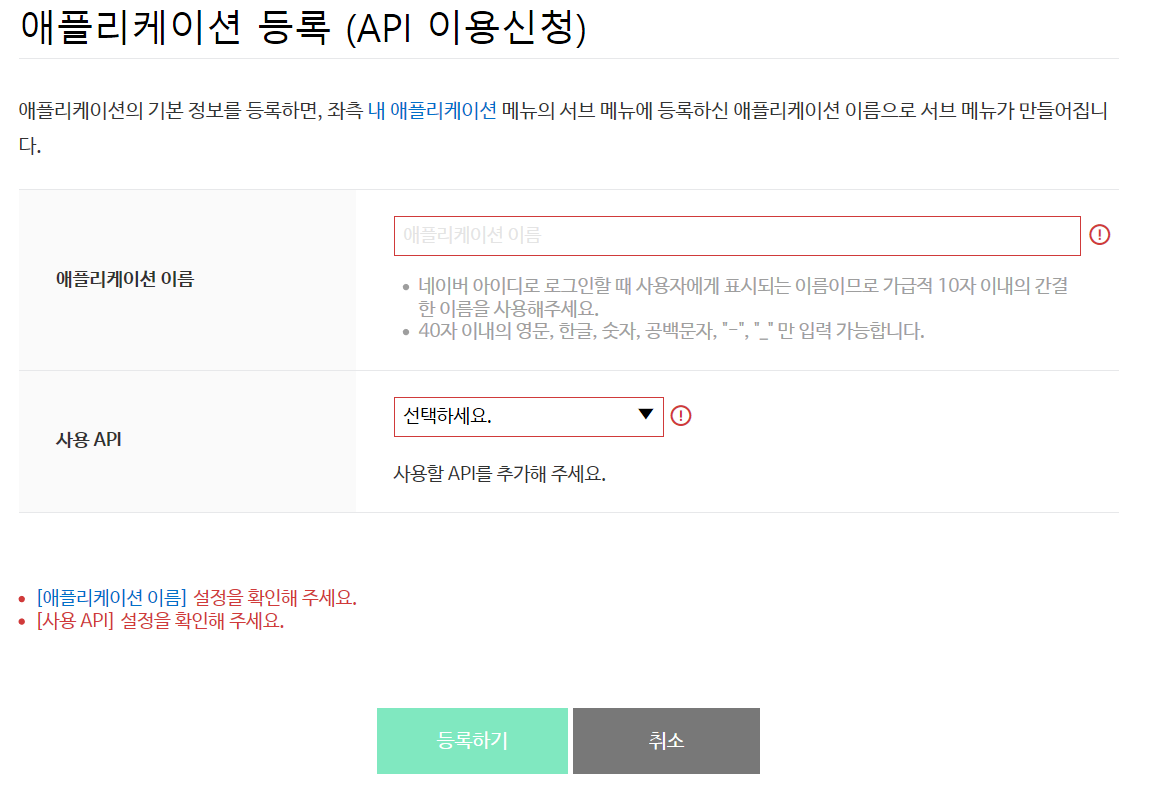
애플리케이션의 이름 및 사용하는 api 등을 선택합니다. ‘검색’을 선택합니다.
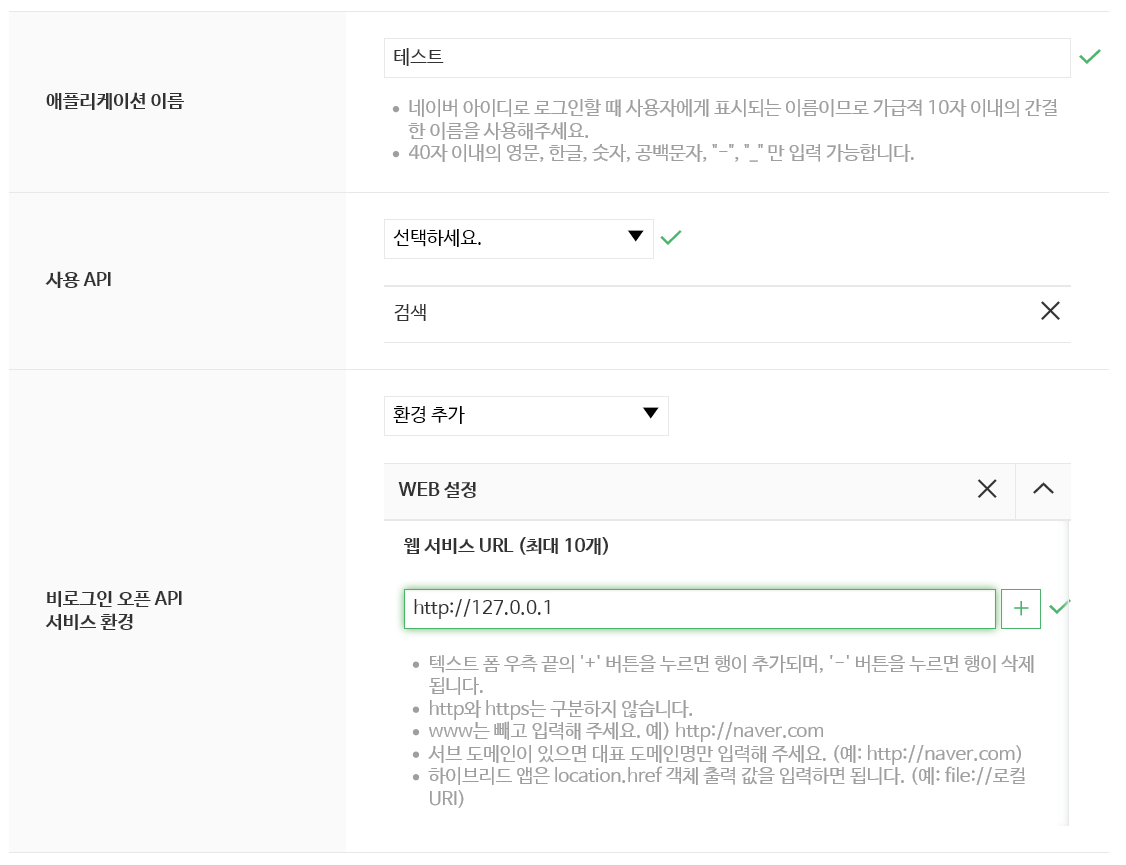
그후 비로그인 오픈 api 서비스 환경이라는 항목이 나타납니다. 안드로이드, IOS 모두 해당되지 않으므로 WEB 설정을 선택하고, 주소는 http://127.0.0.1/ 을 입력합니다. 자기 자신의 컴퓨터 ip를 가리키는 주소입니다. 이제 등록하기를 누르면 앱 생성이 완료됩니다.
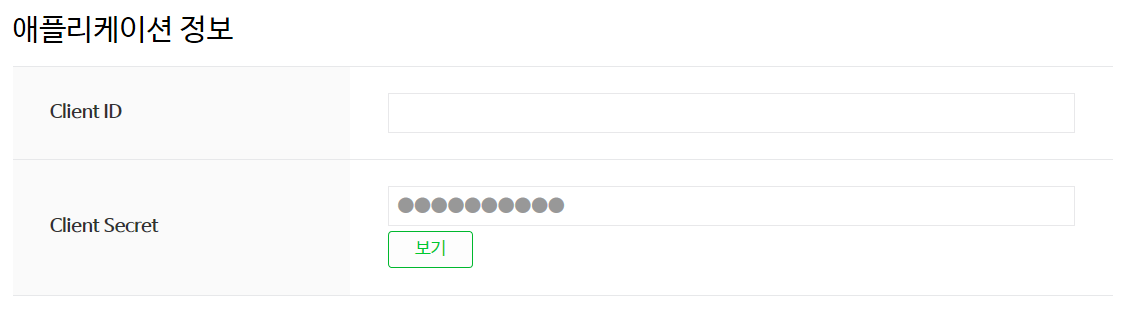
앱 리스트에서 생성된 앱을 확인하고 Client ID와 Client Secret을 잘 보관합니다. Client ID와 Client Secret은 api에서 요청을 한 사람을 식별하고, 권한을 체크할 때 사용합니다. 타인에게 노출되지 않게 조심하시기 바랍니다.
이제 api를 사용할 기본적인 준비는 완료되었습니다. 이제 R에서 api를 불러오고, 결과를 저장하도록 함수를 만들어보겠습니다.
URL 인코딩
퍼센트 인코딩(링크)라고도 합니다. 각 인코딩의 16진수 표현에 %를 붙여 표시하는 인코딩 형태입니다. R에는 기본적으로 utils 패키지에 URL 인코딩 함수 URLencode()가 있습니다. 한글을 변환할 경우 iconv()함수를 통해 UTF-8 인코딩으로 된 문자열을 값으로 지정해줘야 합니다.

- R에서 네이버 API 호출하기
본격적으로 R에서 네이버 api를 호출할 설정을 하겠습니다. api를 호출할 때는 GET 프로토콜을 사용합니다.
api_url = "https://openapi.naver.com/v1/search/webkr.xml"
우선 api의 url을 지정합니다. 위의 경우는 ‘웹문서’에 대한 검색결과를 xml 포맷으로 반환받게 됩니다. 전체 목록 및 api 별 상세 설명은 https://developers.naver.com/ 에서 확인하시기 바랍니다.
- 블로그(XML 포맷) : https://openapi.naver.com/v1/search/blog.xml
- 뉴스(json 포맷) : https://openapi.naver.com/v1/search/news.json
- 영화(XML 포맷) : https://openapi.naver.com/v1/search/movie.xml
query = URLencode(iconv("안드로이드", to="UTF-8"))
query = str_c("?query=", query)
다음은 검색어를 URLencode()를 이용하여 URL 인코딩 형식으로 변환하고, 필요한 부분을 붙여줍니다.
result = GET(str_c(api_url, query),
add_headers("X-Naver-Client-Id" = client_id, "X-Naver-Client-Secret" = client_secret))
앞에서 얻은 클라이언트 id와 secret을 입력하고, GET()을 실행하면 xml 포맷의 결과 데이터를 얻을 수 있습니다.
GET 프로토콜은 대부분 필요한 정보가 url 안에 다 들어가게 되어 있으나, 네이버 api 같은 경우는 url 외부에 정보를 따로 지정해서 전송합니다. 보안에 대한 이유가 아닐까 추측합니다만, 정확하지는 않습니다.
xml_ = xmlParse(result)
xmlParse()를 이용하여 파싱합니다.
xpathSApply(xml_, "/rss/channel/item/title", xmlValue)
xpathSApply(xml_, "/rss/channel/item/link", xmlValue)
xpathSApply(xml_, "/rss/channel/item/description", xmlValue)
이제 xpath를 통해 결과를 얻을 수 있습니다.
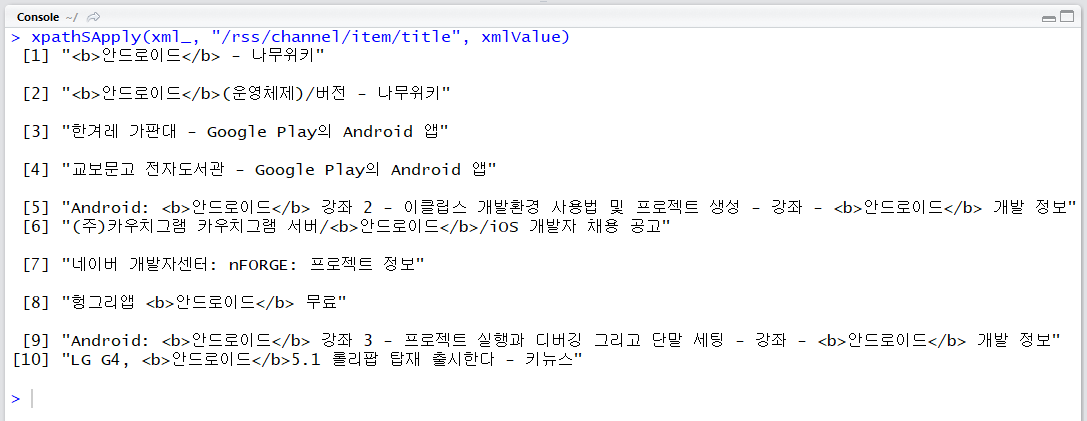
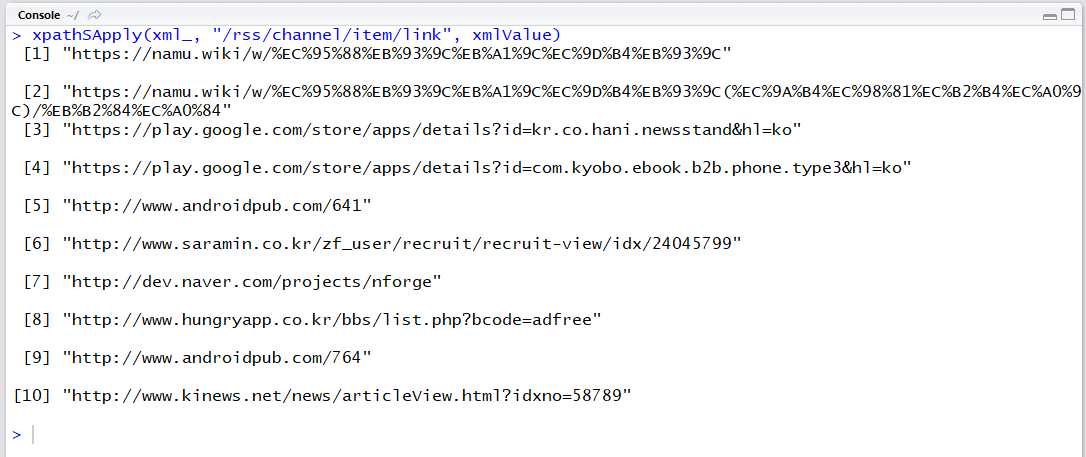

검색 결과에 대해 웹 문서의 제목, 주소, 내용의 일부를 얻을 수 있었습니다. 이제 api에서 query인수 외의 display, start 등의 인수를 조절하면서 자동화하면 지정된 키워드에 대해 정보를 탐색할 수 있습니다.
검색 결과 표시 개수 조정
display_ = "&display=50"
result = GET(str_c(api_url, query, display_),
add_headers("X-Naver-Client-Id" = client_id, "X-Naver-Client-Secret" = client_secret))
xml_ = xmlParse(result)
xpathSApply(xml_, "/rss/channel/item/title", xmlValue)
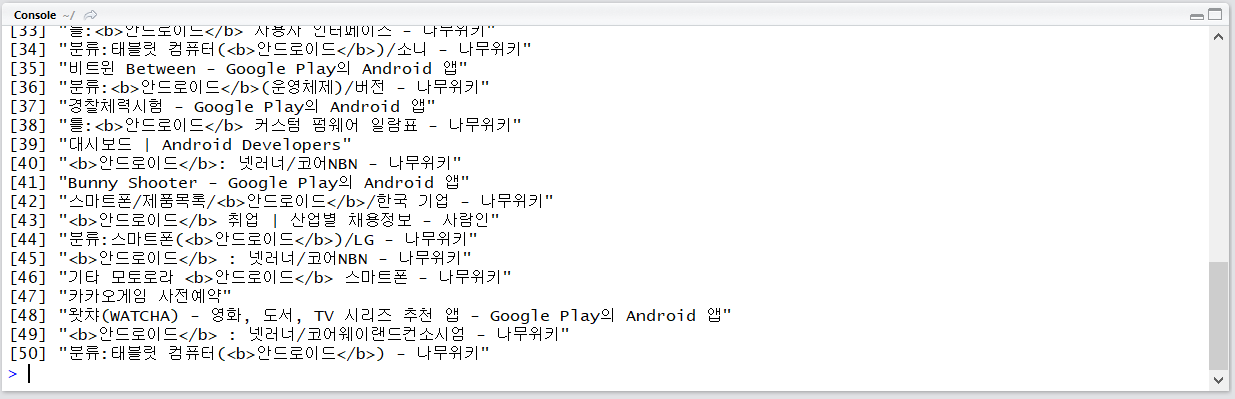
검색 결과 출력 시작 위치 조정
start_ = "&start=50"
result = GET(str_c(api_url, query, start_),
add_headers("X-Naver-Client-Id" = client_id, "X-Naver-Client-Secret" = client_secret))
xml_ = xmlParse(result)
xpathSApply(xml_, "/rss/channel/item/title", xmlValue)
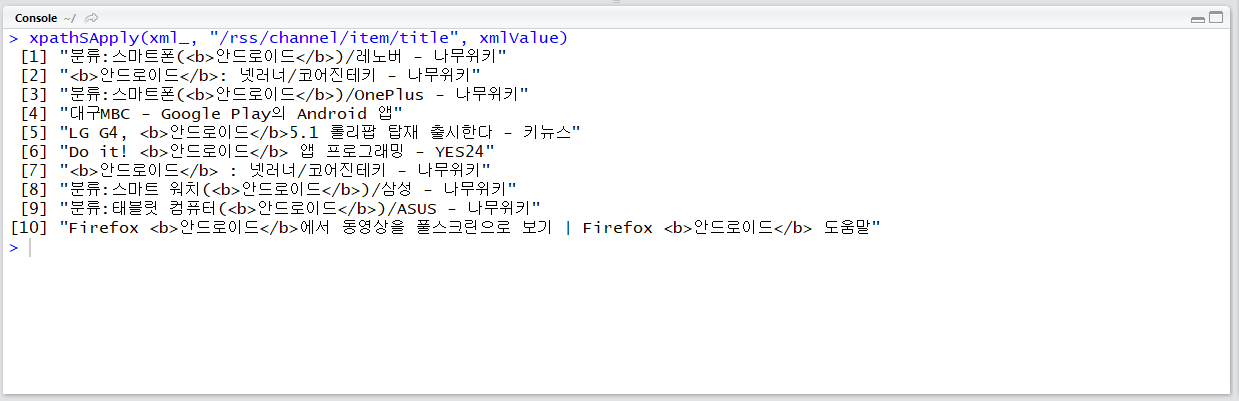
검색 결과 정렬 기준을 날짜순으로
sort_ = "&sort=date"
result = GET(str_c(api_url, query, sort_),
add_headers("X-Naver-Client-Id" = client_id, "X-Naver-Client-Secret" = client_secret))
xml_ = xmlParse(result)
xpathSApply(xml_, "/rss/channel/item/title", xmlValue)
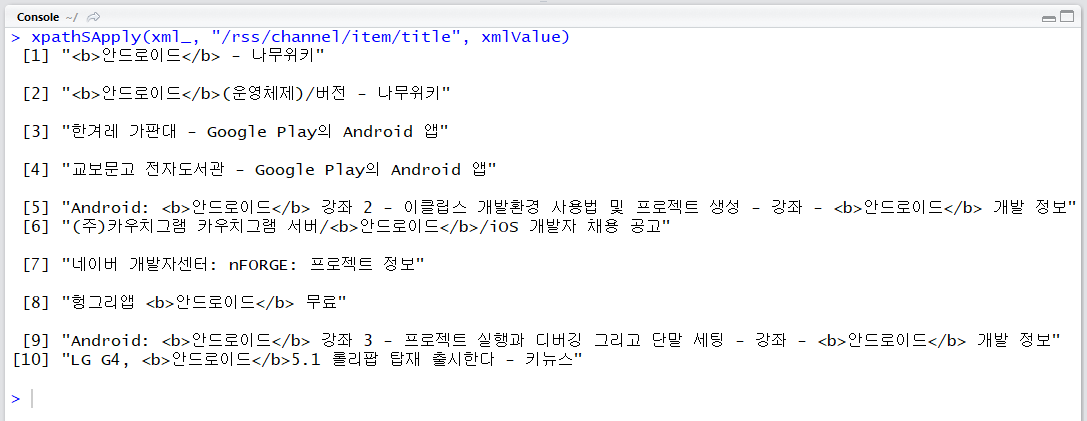
웹 문서의 경우 작성일을 알기가 힘들어서인지 sort 설정이 먹히지 않아 sort=sim인 경우와 동일한 결과가 나옵니다. 뉴스나 블로그 검색 등에서는 정상적으로 작동할 것입니다.
위의 결과 전부 적용
result = GET(str_c(api_url, query, display_, start_, sort_),
add_headers("X-Naver-Client-Id" = client_id, "X-Naver-Client-Secret" = client_secret))
xml_ = xmlParse(result)
xpathSApply(xml_, "/rss/channel/item/title", xmlValue)
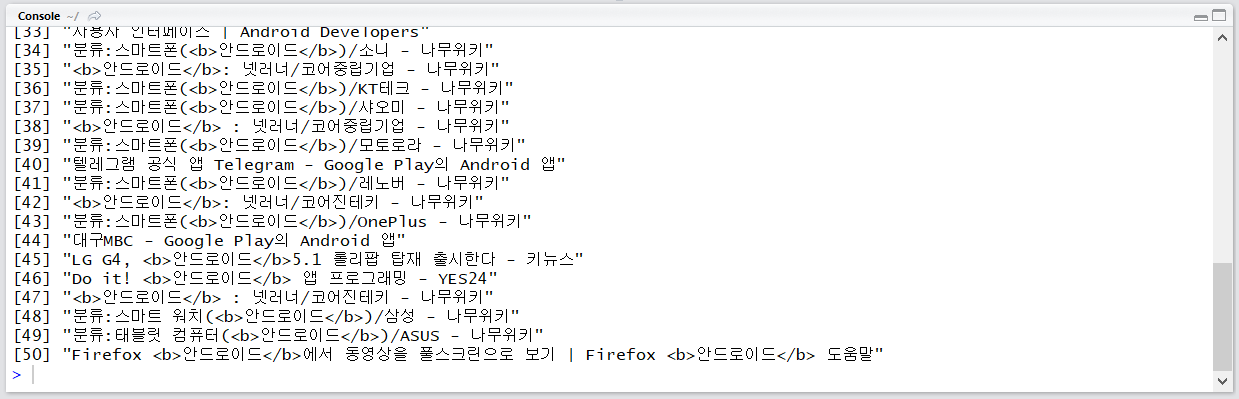
검색 결과 출력 위치를 1, 101, 201, … , 901, 1000으로 바꾸면서 검색 결과를 100개씩 표시하게 하면 키워드 하나 당 1099개의 검색 결과를 얻을 수 있을 것입니다. 정말 아쉬운 건 날짜 기간을 조절할 수 없는 점입니다. 이 점은 카카오 api로 리뉴얼한 다음 api도 마찬가지입니다만..
다음 포스트에는 다음+카카오 api 사용법도 작성하겠습니다.
아래는 전체 코드입니다.
require(httr)
require(stringr)
require(XML)
api_url = "https://openapi.naver.com/v1/search/webkr.xml"
query = URLencode(iconv("안드로이드", to="UTF-8"))
query = str_c("?query=", query)
client_id = ""
client_secret = ""
result = GET(str_c(api_url, query),
add_headers("X-Naver-Client-Id" = client_id, "X-Naver-Client-Secret" = client_secret))
xml_ = xmlParse(result)
xpathSApply(xml_, "/rss/channel/item/title", xmlValue)
xpathSApply(xml_, "/rss/channel/item/link", xmlValue)
xpathSApply(xml_, "/rss/channel/item/description", xmlValue)
# 검색 결과를 50건 출력 (최대 100건)
display_ = "&display=50"
result = GET(str_c(api_url, query, display_),
add_headers("X-Naver-Client-Id" = client_id, "X-Naver-Client-Secret" = client_secret))
xml_ = xmlParse(result)
xpathSApply(xml_, "/rss/channel/item/title", xmlValue)
# 101번째 검색 결과부터 출력 (최대 1000건)
start_ = "&start=50"
result = GET(str_c(api_url, query, start_),
add_headers("X-Naver-Client-Id" = client_id, "X-Naver-Client-Secret" = client_secret))
xml_ = xmlParse(result)
xpathSApply(xml_, "/rss/channel/item/title", xmlValue)
# 유사도가 아닌 날짜순으로 검색된 결과 출력
sort_ = "&sort=date"
result = GET(str_c(api_url, query, sort_),
add_headers("X-Naver-Client-Id" = client_id, "X-Naver-Client-Secret" = client_secret))
xml_ = xmlParse(result)
xpathSApply(xml_, "/rss/channel/item/title", xmlValue)
# 위의 결과 전부 적용
result = GET(str_c(api_url, query, display_, start_, sort_),
add_headers("X-Naver-Client-Id" = client_id, "X-Naver-Client-Secret" = client_secret))
xml_ = xmlParse(result)
xpathSApply(xml_, "/rss/channel/item/title", xmlValue)