R에서 인터넷 자료 불러오기
R · 케이플러스 한성탁 ·R에서 인터넷 자료 불러오기
1. 파일에 직접 접근
1.1 Rstudio의 Import Dataset 버튼 이용하기
이용하고자 하는 데이터 파일이 txt, csv 파일 등인 경우 별도의 작업 없이 데이터를 불러올 수 있습니다.
Rstudio의 오른쪽 상단 Environment에서 Import Dataset을 클릭한 다음 From csv를 선택합니다. 이름은 From csv라고 되어 있으나 공백, 탭, 콤마 등으로 구분된 파일이면 어느 것이든 가능합니다.
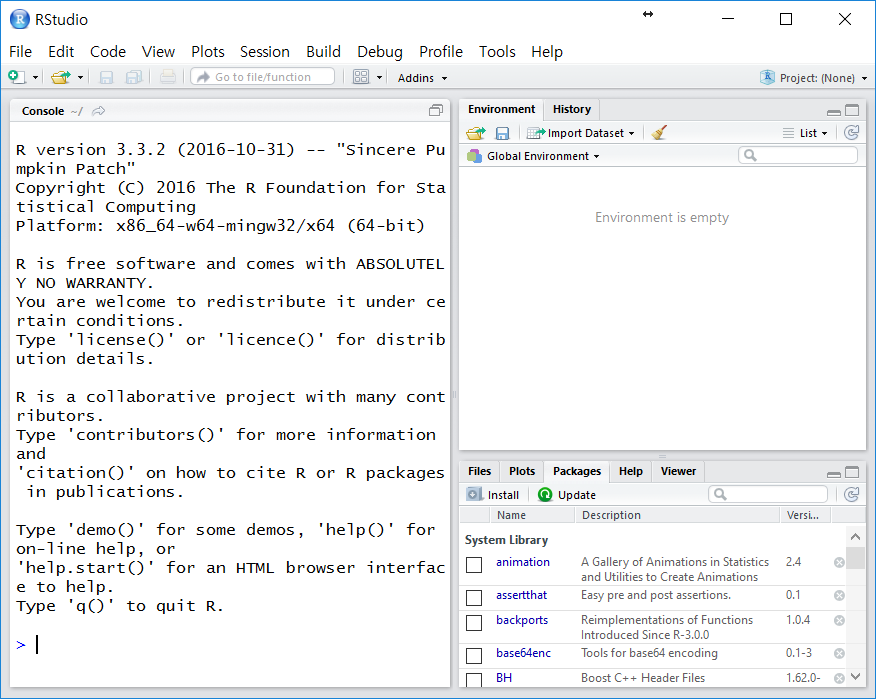
File/URL 란에 원하는 데이터 주소를 입력합니다.
http://www.sample-videos.com/csv/Sample-Spreadsheet-10-rows.csv
를 입력해 보겠습니다.
데이터가 어떻게 불러와지는지 바로 확인할 수 있으며, 기타 옵션도 지정할 수 있습니다.
- Name : 불러올 데이터가 저장될 객체 이름
- Skip : 데이터로 취급하지 않고 불러오지 않을 줄 수
- First Row as Names : 첫 줄을 각 Column의 이름으로 설정할지(= Header 옵션)
- Trim Spaces : 연속된 공백 제거
- Open Data Viewer : 데이터 불러온 후 데이터 뷰어를 볼지 결정
- Delimiter : 데이터 구분 단위(공백, 탭, 콤마, 세미콜론 등)
- Quates : 따옴표 처리(데이터 내에 Delimiter가 들어간 경우 등을 위해)
- Escape : 백슬래시(\)등의 탈출문자 처리
- Comment : 주석으로 인식할 문자 설정
- NA : 결측값으로 인식할 문자 설정
- Locale : 언어 옵션(Encoding 외에는 따로 건들 부분은 없는 것 같습니다)
- Encoding : 자료의 인코딩 방식(EUC-KR이나 기타 인코딩으로 저장된 파일의 경우는 코드로 불러와야 합니다)
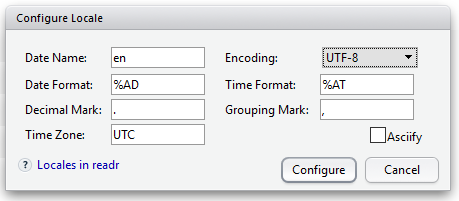
오른쪽 하단에 현재 지정한 옵션에 해당하는 코드를 보여주기 때문에 이 것을 사용해도 무방합니다.
1.2 코드를 이용하여 불러오기
Import Dataset 매뉴를 이용할 경우 “readr” 패키지를 이용합니다만 기본 내장되어 있는 read.table 함수에서도 인터넷 csv 데이터를 불러올 수 있습니다.
read.table("http://www.sample-videos.com/csv/Sample-Spreadsheet-10-rows.csv", header = F, sep=",", stringsAsFactors=F)
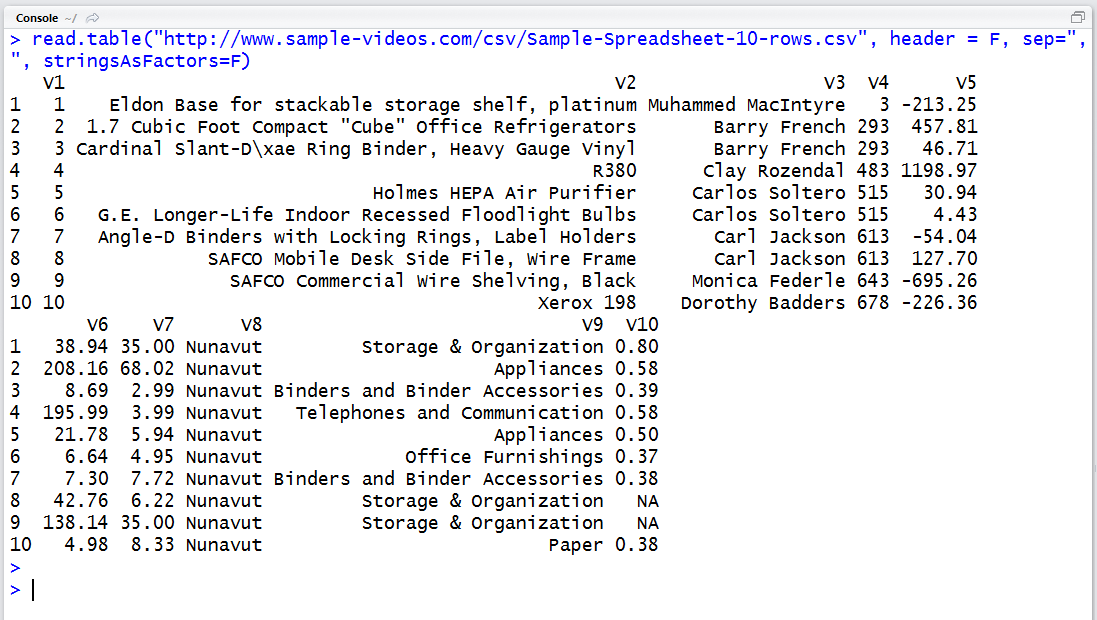
일부 절차가 생략되었을 뿐 데이터를 다운받아 저장한 후 불러오는 과정과 동일합니다. stringsAsFactors 옵션만 주의하시기 바랍니다.
2. 웹페이지에 접근
http 프로토콜인 GET과 POST를 이용해서 데이터를 얻는 과정입니다. 이쪽에 지식이 일천한지라 간단히 구분지으면 GET은 요청할 때 URL에 속성과 값을 붙여서 요청하고 POST는 URL 대신 내부적으로 요청을 보냅니다(그래서 파일이나 이미지 등도 요청에 포함시킬 수 있습니다).
2.1 POST
부산대 맞춤법 검사기가 POST 방식을 이용하는데, 웹페이지에서 직접 입력하는 대신 R에서 접근하여 맞춤법 검사기를 이용해보겠습니다.
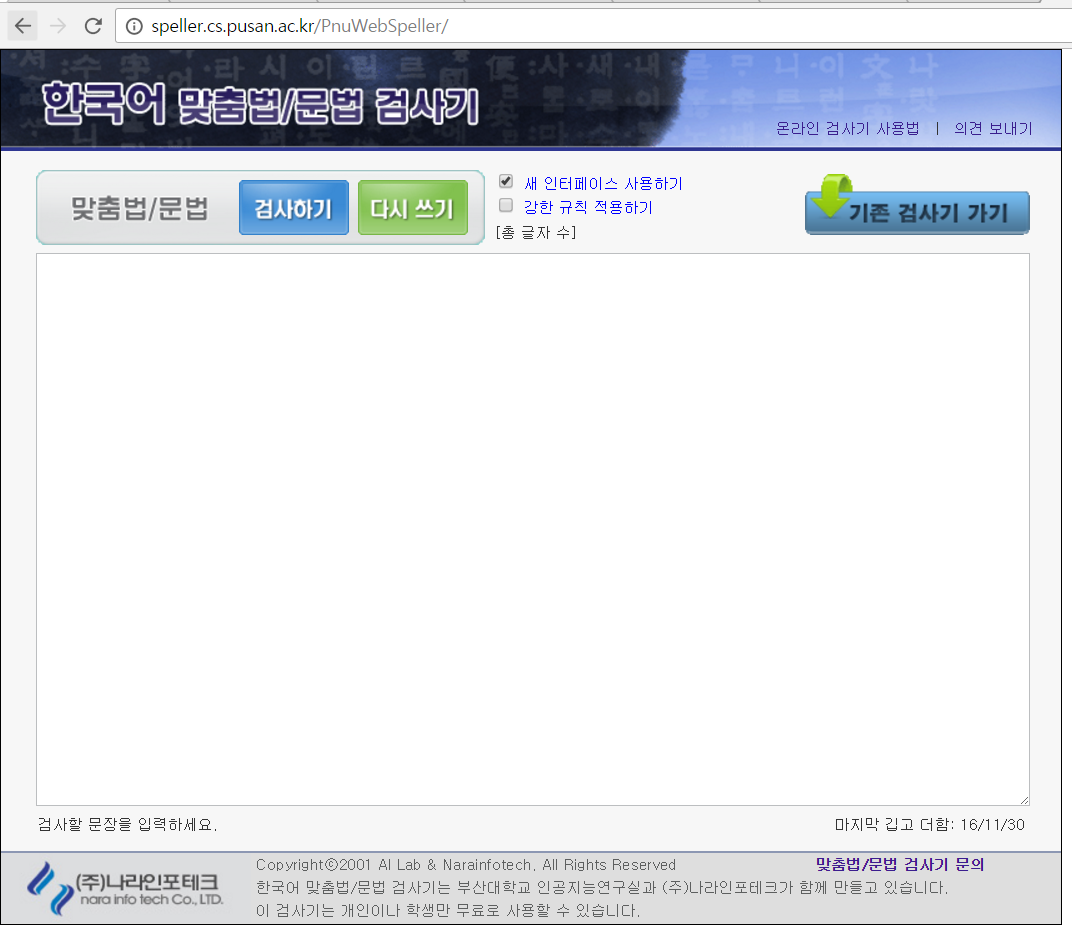
소스 코드를 확인합니다. 크롬 기준으로 단축키 ctrl+U 를 사용합니다.
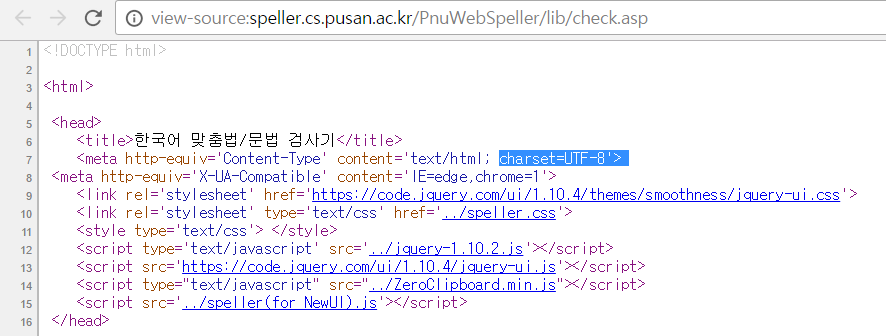
맨 윗부분을 보면 이 페이지의 인코딩 방식은 UTF-8 방식인 것을 확인할 수 있습니다.

소스 코드를 보면 form 태그 부분에 post 방식으로 호출하는 부분이 있는 것을 볼 수 있습니다. 호출 주소는 http://speller.cs.pusan.ac.kr/PnuWebSpeller/ + lib/check.asp 이므로 http://speller.cs.pusan.ac.kr/PnuWebSpeller/lib/check.asp 이고, POST 내용의 데이터 이름은 text1인 것을 볼 수 있습니다. 이것을 이용해서 R에서 POST로 접근해보겠습니다.
post.result = POST("http://speller.cs.pusan.ac.kr/PnuWebSpeller/lib/check.asp",
body = list(text1 = "도너츠 존맛"), encode = "form")
html = htmlParse(post.result, encoding = "UTF-8")
xpathSApply(html, "//td[@class='tdErrWord']", xmlValue)
xpathSApply(html, "//td[@class='tdReplace']", xmlValue)
POST 호출 부분에서 encode의 경우 파일이나 이미지, 문자열 등의 복합적인 요청인 경우 “multipart”, 문자열이면 “form”, “json”, “raw” 등이 있습니다. 여기서는 form을 사용하였습니다.
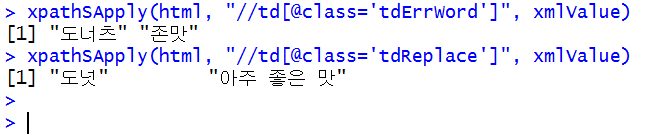
호출된 데이터는 파싱(parsing) 과정을 거쳐 xpath로 추출할 수 있습니다. 파싱이나 xpath 등은 다음에 설명하겠습니다.
2.2 GET
URL을 마치 함수처럼 사용하는 방식입니다. ? 문자 뒤에 인수와 값이 붙고, & 로 구분하여 사용합니다. 네이버, 다음 등 검색엔진에서도 사용하고 있습니다.
https://search.naver.com/search.naver?where=nexearch&query=%EC%98%A4%EB%8A%98&sm=top_hty&fbm=0&ie=utf8
http://search.daum.net/search?w=tot&DA=YZR&t__nil_searchbox=btn&sug=&sugo=&q=%EC%98%A4%EB%8A%98
위의 링크에서 보이듯이 ? 뒤에 여러 가지 인수와 값이 존재하며, 네이버의 경우는 query, 다음의 경우 q가 검색어인 것을 확인할 수 있습니다.
R 내부에서 아마존에 검색어를 입력한 다음 상품 이름을 추출해보겠습니다.
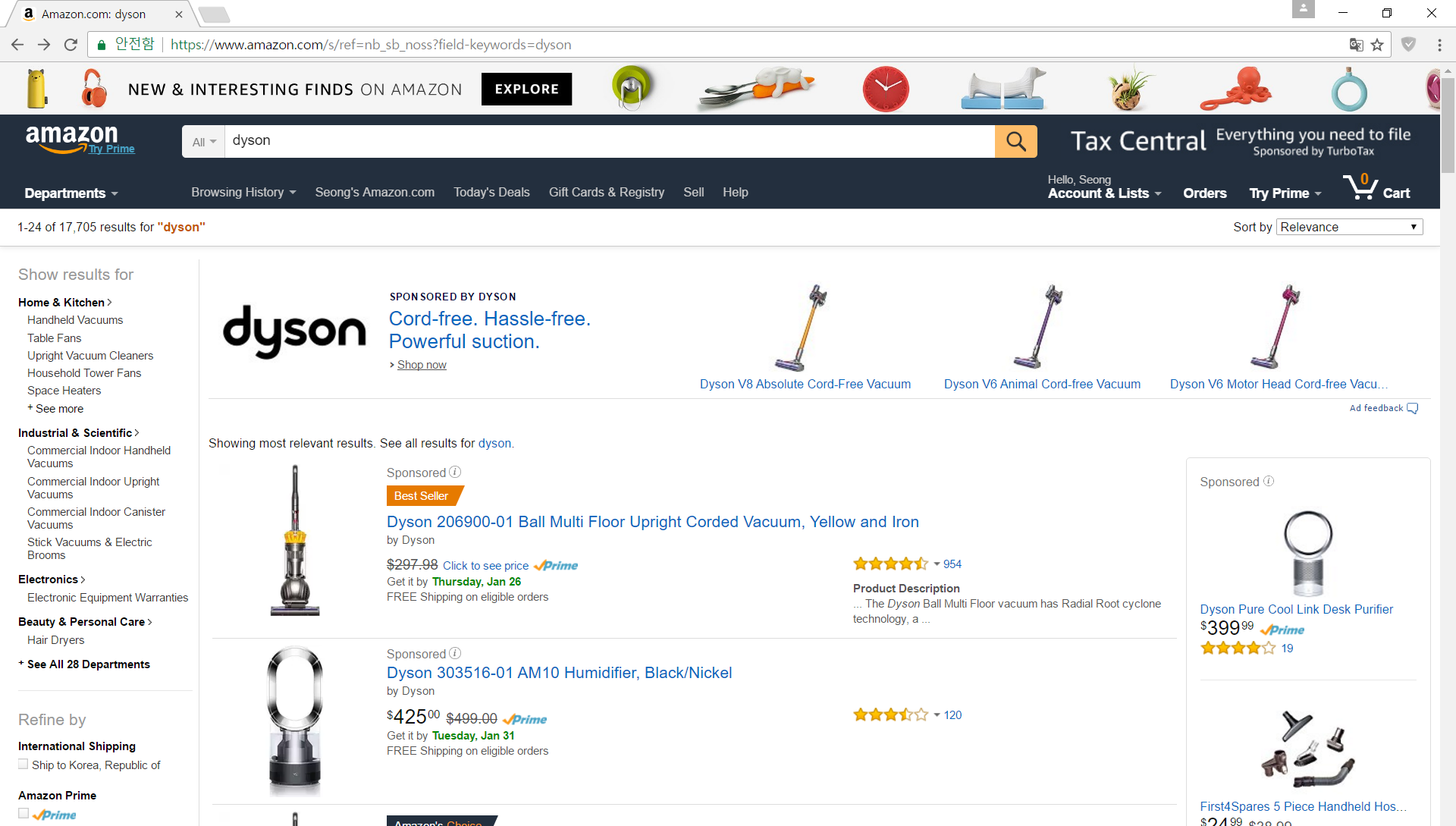
get.result = GET("https://www.amazon.com/s/ref=nb_sb_noss?field-keywords=dyson")
html = htmlParse(get.result, encoding = "UTF-8")
xpathSApply(html, "//div[@id='resultsCol']//div[@class='a-row a-spacing-small']/div[@class='a-row a-spacing-none']/a", xmlValue)
아마존에서는 field-keywords 이라는 인수를 검색어로 사용합니다. 또한 GET을 이용한 호출에는 애드블록 등의 광고 차단 플러그인이 적용되지 않기 때문에 광고 상품이 있어 중복된 결과가 나오는 것을 확인할 수 있습니다.
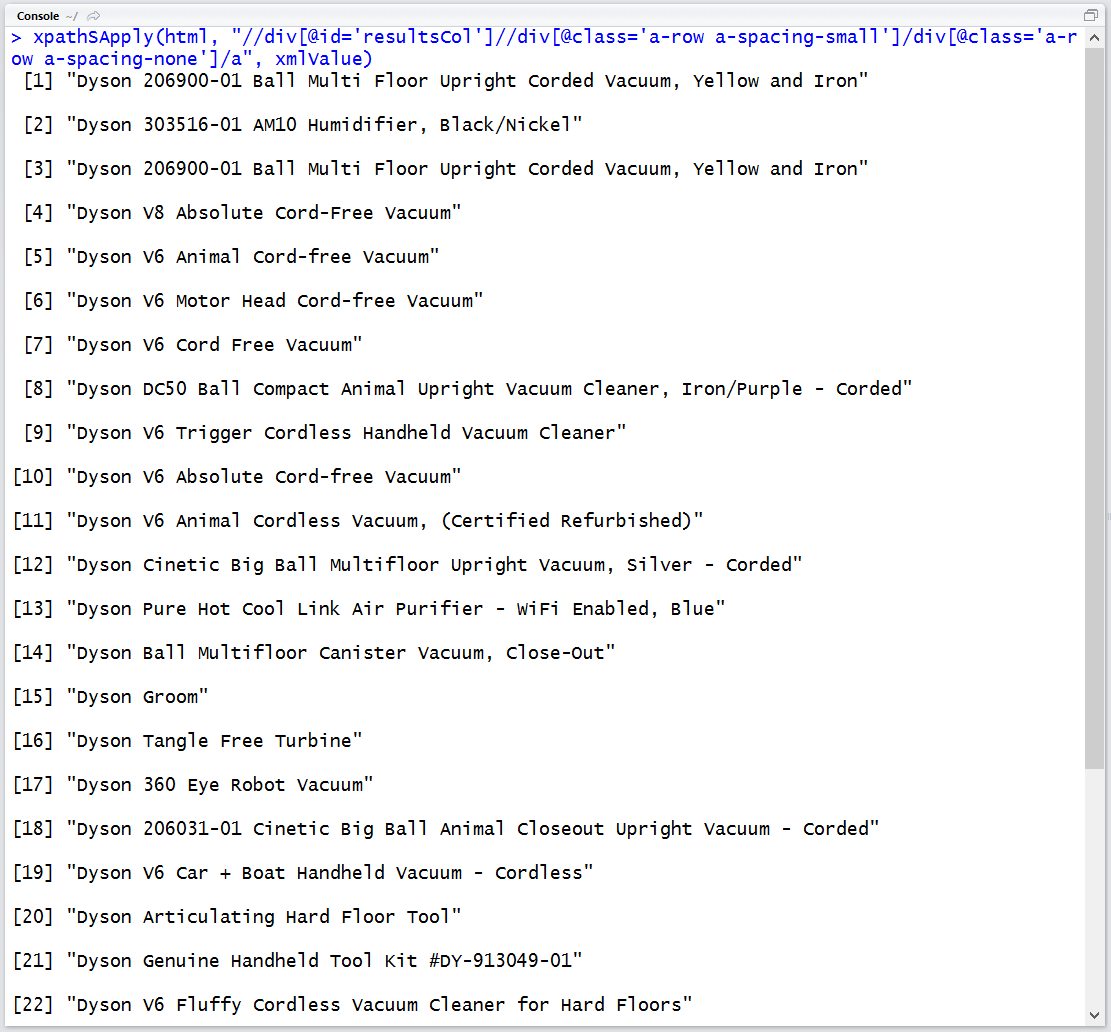
POST의 호출 결과에서도 마찬가지이지만 웹페이지의 결과값은 문자열의 나열이기 때문에 정규식을 이용하거나 파싱, xpath에 의한 추출에 의해 데이터를 얻어야 합니다. 이는 다음 포스트에서 다뤄보겠습니다.