R과 xpath를 이용하여 인터넷 기사 크롤링하기
R · 케이플러스 한성탁 ·다른 포스트에서 xpath에 대해 간단히 설명했습니다. 이번엔 구체적인 예제로써 BBC의 인터넷 기사를 수집해보겠습니다. 환경은 R 3.3.3 버전입니다.
우선 BBC 홈페이지의 구조를 간단히 파악하기 위해서 http://www.bbc.com/news에 들어갑니다.
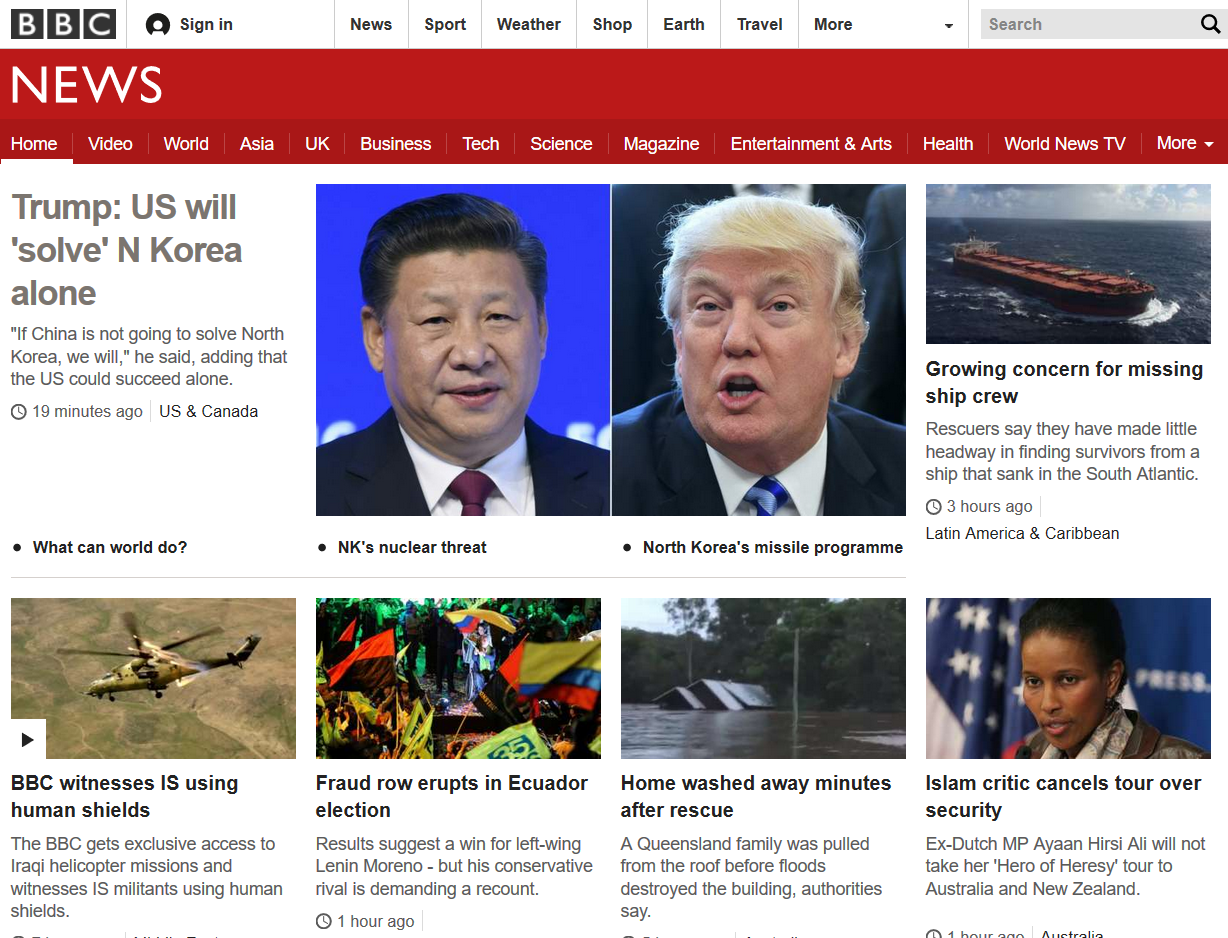
이렇게 격자형으로 구성되어 있는 사이트는 독자 입장에서는 좋을 수 있으나 수집하는 입장에서 좋지는 않습니다.
기사 수집 시에는 기사들이 목록화되어 있는 것이 좋습니다. 그래도 기사를 수집해보겠습니다. 아래를 스크롤을 내리면 많은 기사들이 있지만, 상단 부분의 톱 기사만 추출하겠습니다. 개발 도구(대부분의 브라우저에서 F12 또는 Ctrl+Shift+I)를 엽니다.
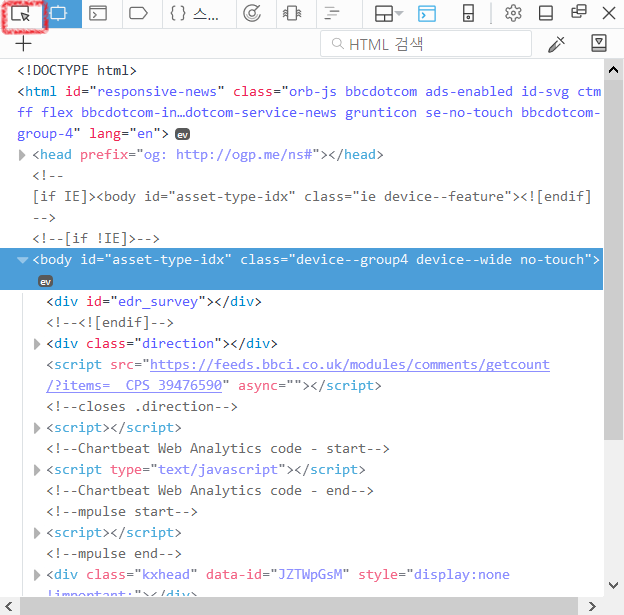
마우스 커서가 있는 아이콘을 클릭한 다음, 뉴스 제목 부분을 다시 클릭합니다. 그러면 현재 사이트 구조에서 클릭한 부분의 부분을 찾아줍니다.
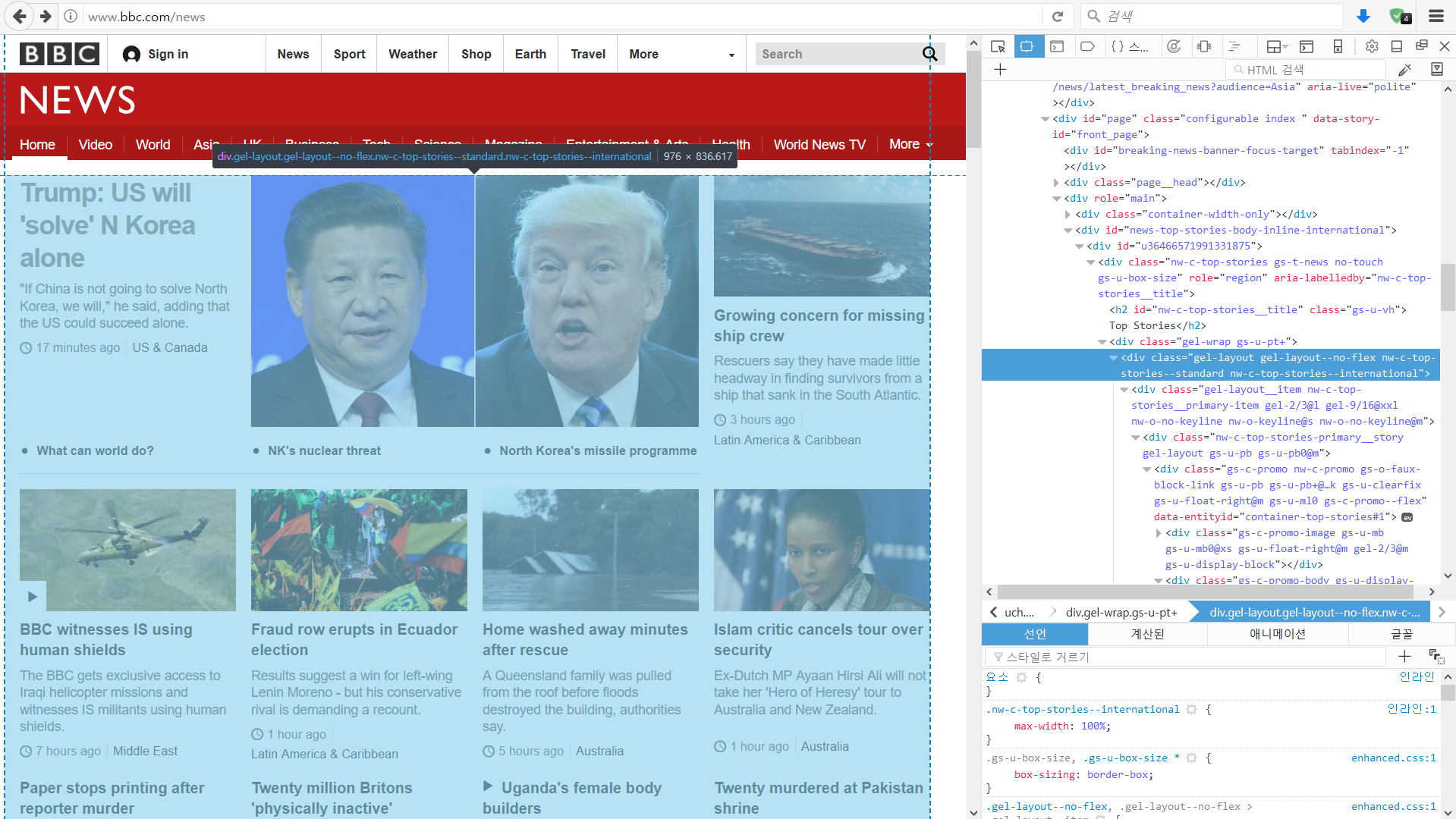
마우스 커서를 이리 저리 움직이며 살펴보면 톱 기사 부분에 대한 영역이 선택됩니다. 클릭 시 고정됩니다. 오른쪽에 나오는 정보를 메모해놓아야 합니다. 매우 긴 이름의 class 속성을 가진 <div> 태그입니다.
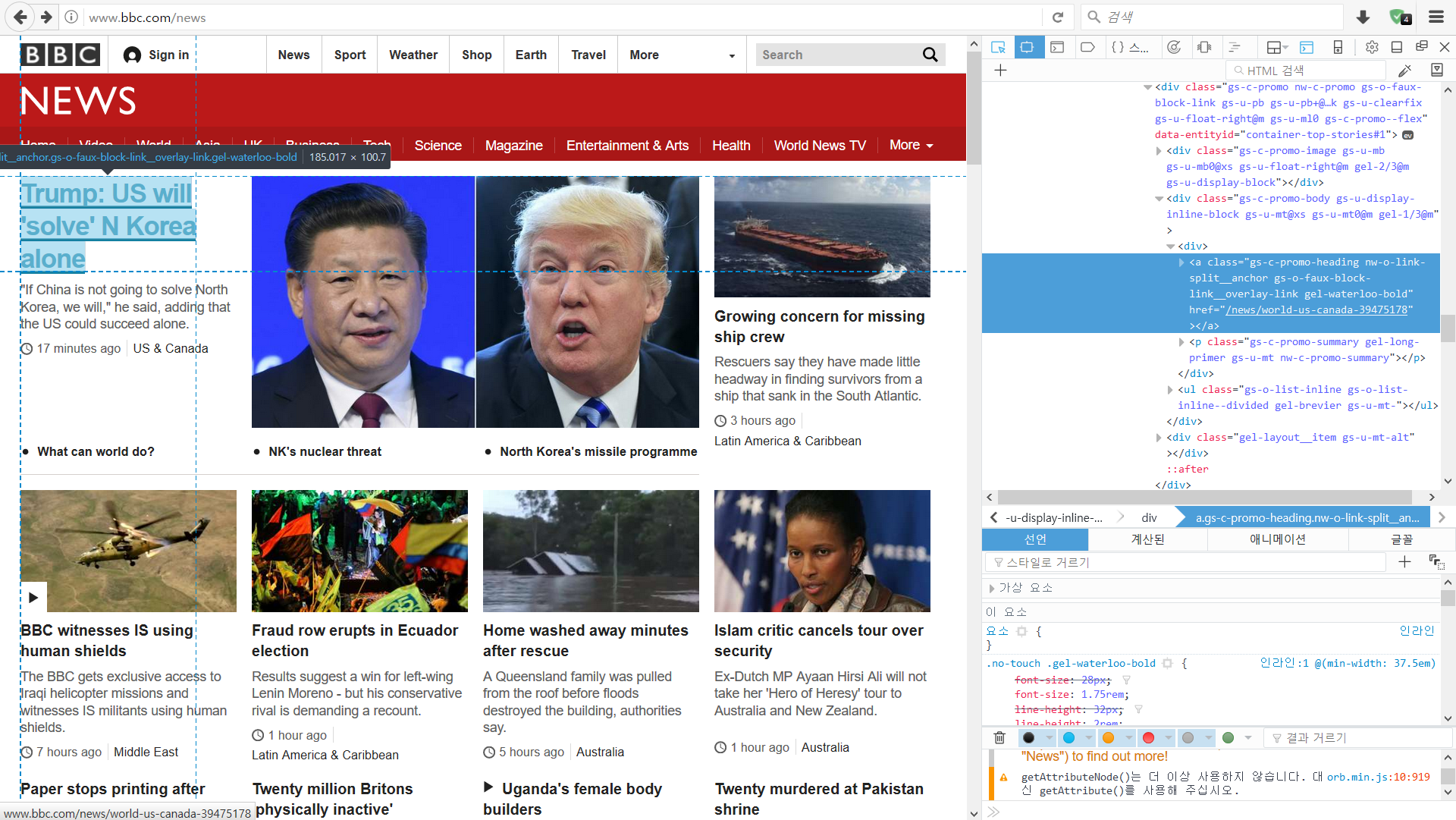
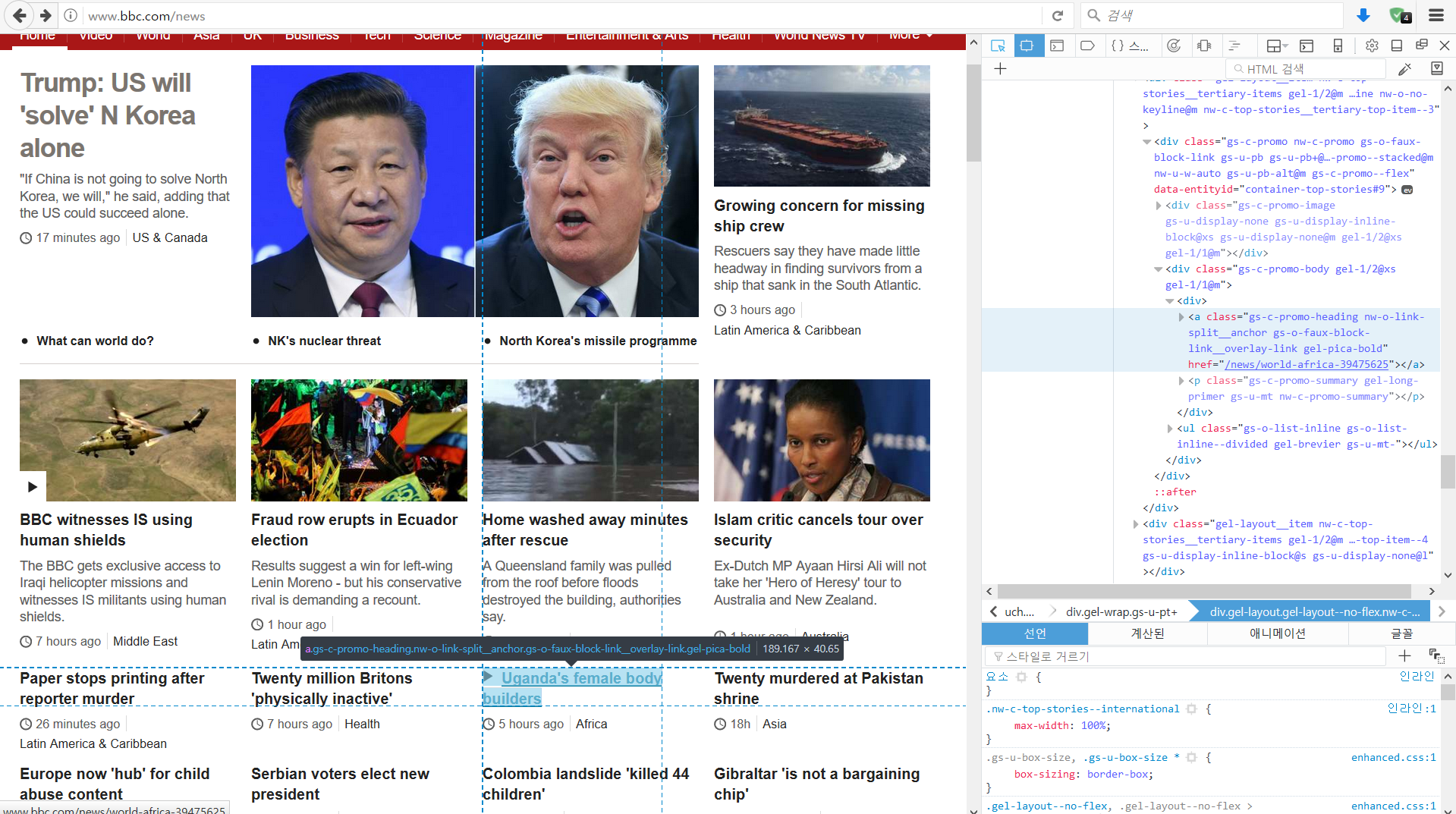
기사의 경우는 <a> 태그입니다. 크롬의 경우 하이라이트 되어 있는 부분에 오른쪽 클릭을 하면, 해당 부분의 xpath 주소를 바로 복사할 수 있습니다. 이 xpath 주소를 이용하여 크롤링하면 사이트의 구조가 아주 약간만 바뀌어도 오류가 발생하므로, 직접 xpath를 구해보겠습니다.
<div> 태그에 class 속성이 있고 그 아래 계층에 여러 잡다한 태그가 있으며, <a>에 뉴스 기사의 URL 주소와 제목이 있습니다. 이 구조는 다음과 같습니다.
- div (class = a)
- …
- …
- <a (class = b href=기사 URL) > 기사 제목 </a>
- <a (class = c href=기사 URL) > 기사 제목 </a>
- …
- <a (class = c href=기사 URL) > 기사 제목 </a>
- …
- …
톱 기사 div 영역의 class는 gel-layout gel-layout–no-flex nw-c-top-stories–standard nw-c-top-stories–international입니다. 사람에게 보여지는 속성을 지정하는 영역이라 매우 긴 이름을 가지고 있습니다. 이름 중 top-stories–international 부분이 국제 톱 기사를 말하는 것이라고 가정 하겠습니다.
뉴스 링크 a 영역의 class는 gs-c-promo-heading nw-o-link-split__anchor gs-o-faux-block-link__overlay-link gel-pica-bold입니다. promo-heading이 헤드라인에 대한 속성이라고 가정하고 추출해보겠습니다.

BBC 홈페이지의 인코딩은 utf-8입니다. 인코딩은 간단히 컴퓨터 내부에서 문자를 기록하는 방식을 말합니다. 우리나라 홈페이지의 인코딩은 대부분 euc-kr 또는 utf-8이며, utf-8은 많은 웹사이트에서 널리 쓰입니다. R에서는 euc-kr의 상위호환인 CP949를 사용할 수도 있습니다.
library(XML)
library(httr)
library(stringr)
URL = "http://www.bbc.com/news"
get0 = GET(URL)
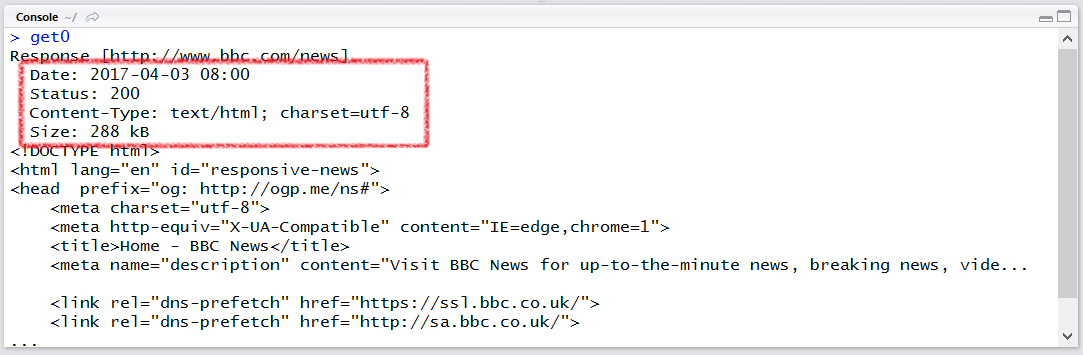
GET()으로 정보를 얻어오면 각종 메타데이터가 표시됩니다. 위 결과를 보시면 Status는 200인데 이건 GET 요청이 잘 처리되었다는 코드입니다. 403, 404등이 에러 코드입니다. Content-Type부분을 보면 charset이 utf-8인 것을 확인할 수 있습니다.
html0 = htmlParse(get0, encoding = "UTF-8")
xpath1 = "//div[contains(@class,'top-stories--international')]"
xpath2 = "//a[contains(@class,'promo-heading')]"
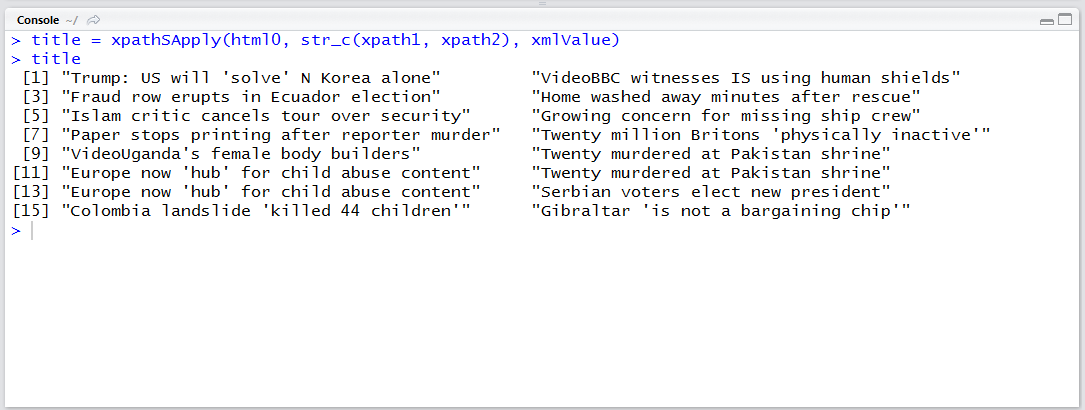
xpathSApply(html0, xpath1, xmlValue)
xpathSApply(html0, xpath2, xmlValue)
GET()의 반환값은 아직 문자열의 나열일 뿐 구조적인 형태는 아닙니다. htmlParse()를 이용하여 파싱을 하였습니다. 인코딩 형식도 지정하여 줍니다.
xpathSApply()를 통해 잘 실행되었는지 확인합니다. 특히 xpathSApply(html0, xpath1, xmlValue) 부분이 length 2 이상의 데이터로 반환된다면 구역이 여러 개 선택된 것이므로 수정이 필요할 것입니다.
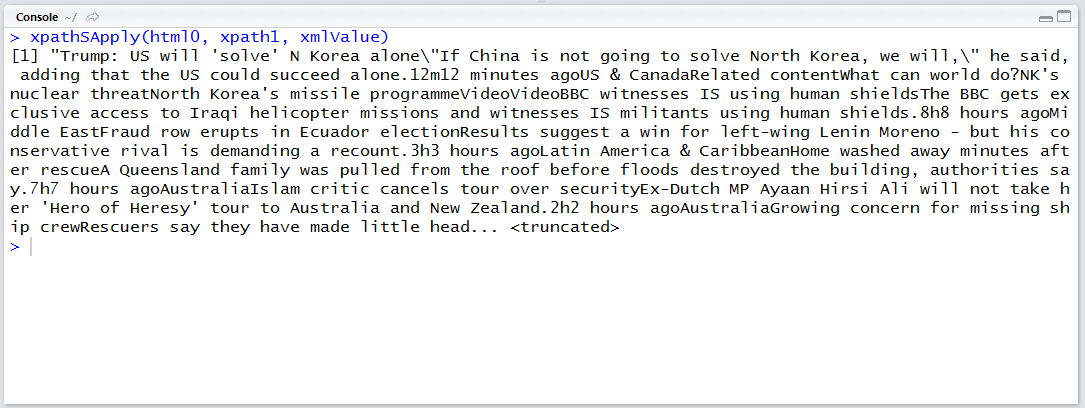
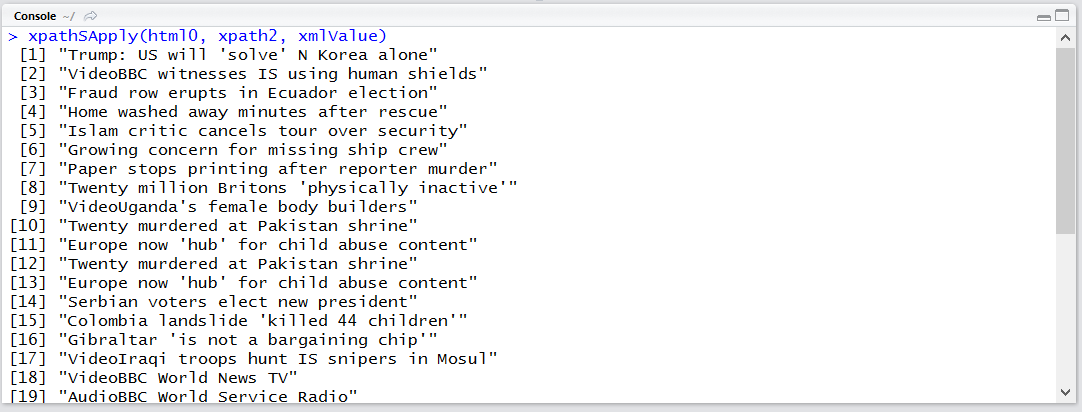
하나의 구역만 선택되었으며 기사 제목이 잘 표시됩니다.
저는 여기서 xpathSApply()를 사용했는데, xpathApply()를 사용하면 찾은 함수에 바로 함수까지 적용시켜줍니다. xpathApply(html, xpath, FUN)은 lapply(getNodeSet(html, xpath), FUN)과 같습니다. xpathSApply는 lapply()대신 sapply()입니다. 추출한 노드는 하위 노드의 정보를 모두 포함하고 있습니다. 별도의 작업 없이 일단 노드만 추출하려면 getNodeSet()을 사용하면 됩니다.
이제 xpath 두개를 합쳐서 톱 기사 부분의 기사만 가져오겠습니다.
텍스트 노드의 값을 갖고오는 함수는 xmlValue(), 속성을 갖고 오는 함수는 xmlAttrs()입니다.
title = xpathSApply(html0, str_c(xpath1, xpath2), xmlValue)
node_href = function(node) xmlAttrs(node)["href"]
url = xpathSApply(html0, str_c(xpath1, xpath2), node_href)
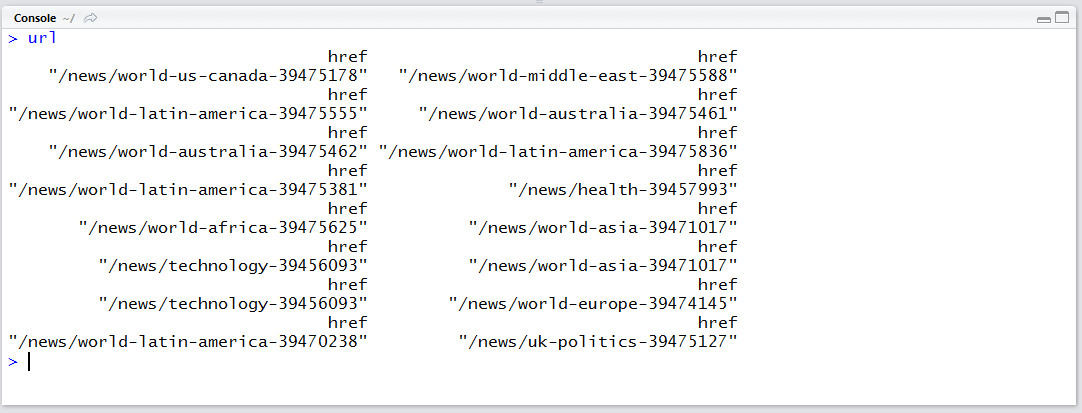
약간 중복되는 항목이 존재하나 잘 추출되었습니다. 적절히 정리하여 데이터 프레임으로 만들어주겠습니다. 특히 URL 부분의 경우 상대적 주소(bbc.com이 생략된 형태)이기 때문에 그 부분을 붙여줘야 합니다.
newslist = data.frame(title = title, url = str_c("http://www.bbc.com", url))
newslist = unique(newslist)
row.names(newslist) = NULL
newslist
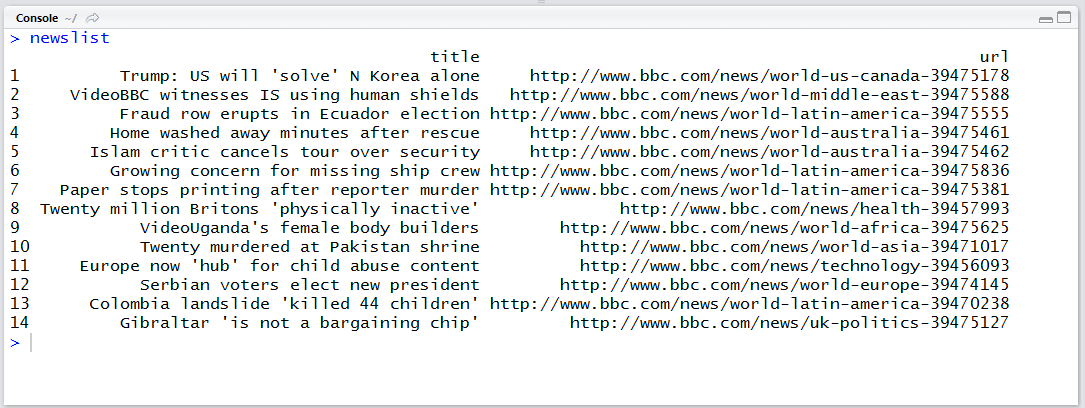
이제 메인 페이지 톱 기사 영역의 뉴스 제목과 URL을 얻었습니다. 다른 페이지도 페이지 주소만 주어지면 동일하게 기사 제목과 URL을 얻을 수 있습니다.
뉴스 사이트에서 기사 URL을 얻었으니 이제 각 기사 본문을 추출해보겠습니다. US gunman kills three ‘in race attack’ 이라는 기사에 들어갔습니다. 개발 도구를 이용해 기사 본문 부분의 구조를 살펴보겠습니다.
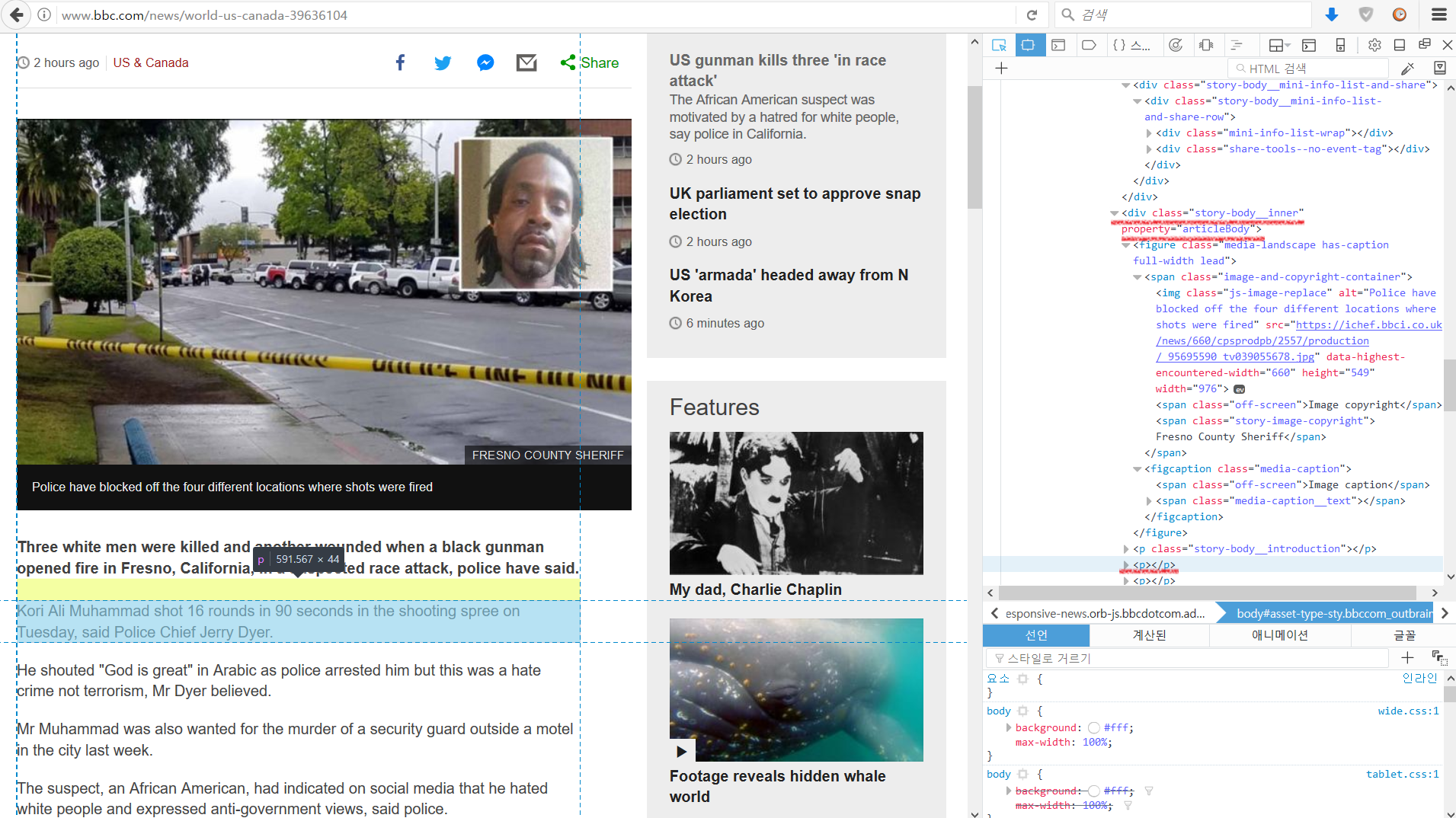
<div> 안의 <p> 태그에 기사 본문들이 있고 div의 속성은 class=”story-body__inner” property=”articleBody” 입니다. 이 것으로 xpath를 만들어서 추출해보겠습니다. 앞에서와 같이 GET()과 htmlParse()는 동일하게 진행하고 URL에 뉴스 기사가 들어갑니다.
URL = newslist$url[1]
get0 = GET(URL)
html0 = htmlParse(get0, encoding = "UTF-8")
xpath3 = "//div[@property='articleBody']/p"
content0 = xpathSApply(html0, xpath3, xmlValue)
content0

결과를 문장 단위로 추출이 됩니다. 이대로 사용해도 되며 str_c() 함수로 합쳐 줄 수도 있습니다. collapse = “ “로 공백을 한 칸 넣으셔야 마침표와 다음 문장이 붙어나오지 않습니다.
content0 = str_c(content0, collapse = " ")
content0

이제 반복문을 통해 10초마다 수집을 하도록 만들어보겠습니다. (반복 한번 당 10초 대기하므로 계산 시간을 생각하면 10초를 약간 넘습니다) 너무 빠른 속도로 수집을 하면 아이피 밴을 당하거나 사람인지 확인하는 CAPTCHA 등의 절차를 통과해야 합니다. 물론 사람인지 확인하는 테스트이므로 R을 통해 통과하기는 어렵습니다.
또한 크롤링을 하실 때에는 사이트의 robots.txt 를 확인하시기 바랍니다. robots.txt 는 크롤링 행위에 대한 권한을 명시해 놓은 파일이며, 사이트의 사이트맵이나 권장하는 크롤링 딜레이 등 여러 정보를 담겨 있습니다.
사이트 마다 크롤링을 허용하는 부분과 불허하는 부분이 다릅니다. 구글의 경우 크롤링에 대한 권한을 매우 자세하게 기술해놓았으며, 네이버의 경우 모든 크롤링을 불허합니다. bbc의 경우 크롤링 봇 종류에 따라 다른 권한을 부여하였습니다. 이 블로그는 모든 크롤링을 허용합니다. robots.txt의 경우 권고안으로 법적 구속력은 없는 것으로 알고 있습니다만 심각한 경우 법적 공방으로 이어질 수도 있습니다.
이 bbc 뉴스 크롤링의 경우 robots.txt에서 disallow 하지 않았으므로 허용되는 부분입니다.
아래는 전체 코드입니다.
library(XML)
library(httr)
library(stringr)
URL0 = "http://www.bbc.com/news"
get0 = GET(URL0)
html0 = htmlParse(get0, encoding = "UTF-8")
xpath1 = "//div[contains(@class,'top-stories--international')]"
xpath2 = "//a[contains(@class,'promo-heading')]"
title = xpathSApply(html0, str_c(xpath1, xpath2), xmlValue)
node_href = function(node) xmlAttrs(node)["href"]
url = xpathSApply(html0, str_c(xpath1, xpath2), node_href)
newslist = data.frame(title = title, url = str_c("http://www.bbc.com", url), stringsAsFactors = F)
newslist = unique(newslist)
row.names(newslist) = NULL
newslist$content = NA_character_
for(i in 1:nrows(newslist)){
URL = newslist$url[i]
get0 = GET(URL)
html0 = htmlParse(get0, encoding = "UTF-8")
xpath3 = "//div[@property='articleBody']/p"
content0 = xpathSApply(html0, xpath3, xmlValue)
content0 = str_c(content0, collapse = " ")
newslist$content[i] = content0
Sys.sleep(10)
}
head(newslist, 2)