R에서 빠르게 데이터 읽기/쓰기
R · 케이플러스 한성탁 ·R은 기본 base 패키지에서 scan(), write(), read.table(), save(), load()등의 데이터 입출력 함수를 가지고 있습니다. 데이터의 크기가 작을 때는 이러한 기본 함수를 사용해도 크게 불편함이 없으나 읽고 쓰는 데이터의 크기가 커질 수록 입출력 함수의 속도가 중요하다고 할 수 있습니다.
숫자 데이터, 문자 데이터의 2종류 데이터에 대해 5가지의 입출력 함수를 사용하여 속도를 비교해 보겠습니다. 테스트 환경은 윈도우 10, R 3.4.1, data.table 1.10.4, readr 1.1.1, feather 0.3.1 이며 저장매체는 M2 SSD입니다.
- write.csv(), read.csv() : base 패키지
- write_csv(), read_csv() : readr 패키지
- fwrite(), fread() : data.table 패키지
- saveRDS(), readRDS() : base 패키지
- write_feather(), read_feather() : feather 패키지
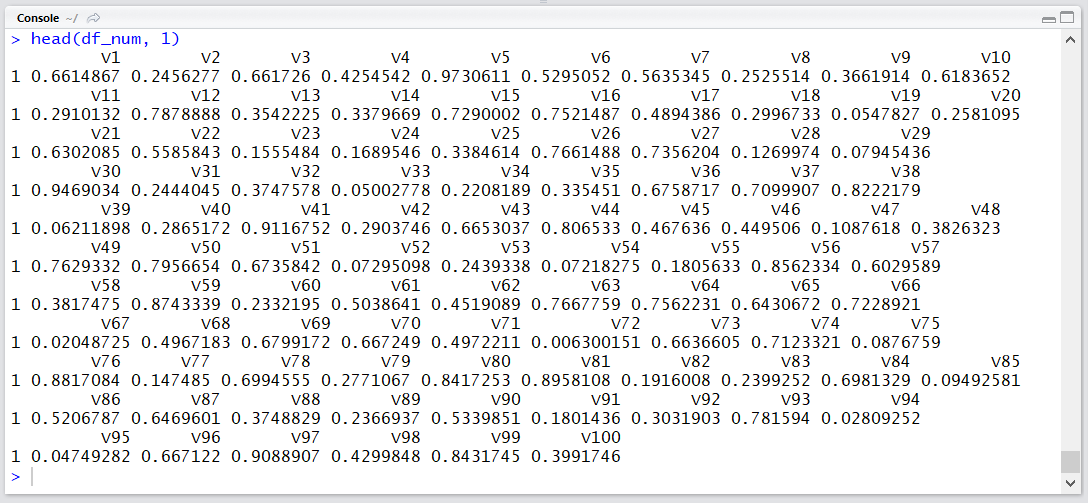
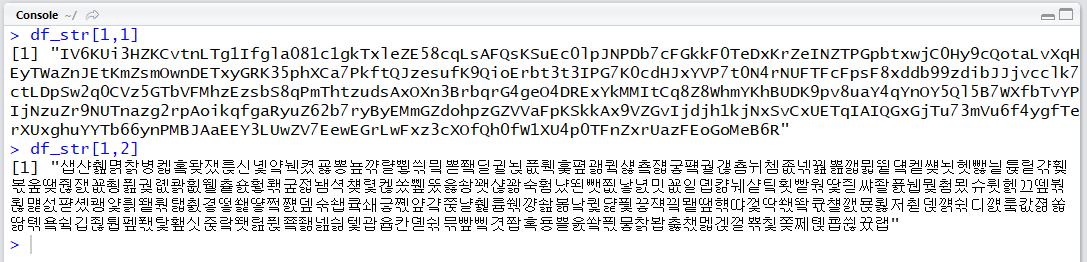
숫자 데이터의 경우 100000행, 100열의 총 1억 개의 0과 1사이의 실수, 문자 데이터의 경우 100000행, 2열이며 500자리의 숫자, 알파벳과 250자리의 한글로 이루어져 있습니다.
require(stringi)
df_num = as.data.frame(matrix(runif(100000*100), 100000, 100))
df_str = data.frame(
stri_rand_strings(100000, 500),
stri_rand_strings(100000, 250, "[가-힣]")
)
먼저 데이터의 압축률부터 보겠습니다.

UTF-8 인코딩의 csv 형식의 경우 압축이 이루어지지 않기 때문에 가장 용량이 많습니다. feather 형식 같은 경우 숫자 데이터에서는 절반 수준의 압축률을 보여주고 있으나, 문자 데이터에서는 오히려 용량이 늘어난 모습입니다. rds 형식의 경우 숫자와 문자 데이터 모두에서 매우 높은 압축률을 보여주고 있습니다. 참고로 csv파일을 7z형식으로 압축 프로그램(반디집)을 이용하여 압축률 최대로 압축할 경우 숫자 데이터는 77Mb, 문자 데이터는 85Mb가 됩니다.
require(microbenchmark)
microbenchmark(write.csv = write.csv(df_num, file="df_num.csv"),
fwrite = fwrite(df_num, file="df_num.csv", col.names = F),
write_csv = write_csv(df_num, path="df_num.csv", col_names = F),
saveRDS = saveRDS(df_num, file="df_num.rds"),
write_feather = write_feather(df_num, path="df_num.feather"),
times = 10, unit = "s")

숫자 데이터의 읽기 속도(mean 기준)를 보면 read_feather()가 압도적으로 빠르며, readRDS(), read_csv(), fread(), read.csv() 순으로 읽기 속도가 빨랐습니다.
require(microbenchmark)
microbenchmark(write.csv = write.csv(df_str, file="df_str.csv"),
fwrite = fwrite(df_str, file="df_str.csv", col.names = F),
write_csv = write_csv(df_str, path="df_str.csv", col_names = F),
saveRDS = saveRDS(df_str, file="df_str.rds"),
write_feather = write_feather(df_str, path="df_str.feather"),
times = 10, unit = "s")

숫자 데이터의 쓰기 속도(mean 기준)를 보면 write_feather()가 가장 빠르며, fwrite(), write_csv(), saveRDS(), write.csv() 순으로 쓰기 속도가 빨랐습니다.
require(microbenchmark)
microbenchmark(read.csv = read.csv(file="df_num.csv", header=F),
fread = fread(file="df_num.csv", header=F, showProgress = F),
read_csv = read_csv(file="df_num.csv", col_names = F, progress = F),
readRDS = readRDS(file="df_num.rds"),
read_feather = read_feather(path="df_num.feather"),
times = 10, unit = "s")

문자 데이터의 읽기 속도(mean 기준)를 보면 read_feather()가 가장 빠르며 fread(), read_csv(), readRDS(), read.csv() 가 뒤를 이었습니다.
require(microbenchmark)
microbenchmark(read.csv = read.csv(file="df_str.csv", header=F),
fread = fread(file="df_str.csv", header=F, showProgress = F),
read_csv = read_csv(file="df_str.csv", col_names = F, progress = F),
readRDS = readRDS(file="df_str.rds"),
read_feather = read_feather(path="df_str.feather"),
times = 10, unit = "s")
문자 데이터의 쓰기 속도(mean 기준)를 보면 fwrite()가 가장 빠르며, write_feather(), write_csv(), saveRDS(), write.csv() 순으로 쓰기 속도가 빨랐습니다.
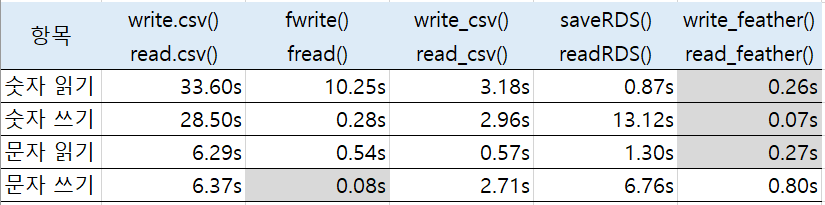
결과를 요약하자면 다음과 같습니다.
- write.csv(), read.csv() : 기본 함수. 권장하지 않음
- fwrite(), fread() : 데이터 압축 없음, 문자 데이터 읽고 쓰기가 빠름, 텍스트 에디터 등으로 바로 열람 가능
- write_csv() read_csv() : 데이터 압축 없음, 무난한 읽기 및 쓰기 속도, 텍스트 에디터 등으로 바로 열람 가능
- saveRDS(), readRDS() : 높은 데이터 압축률, 빠른 읽기 속도, 느린 쓰기 속도
- write_feather() read_feather() : 낮은 데이터 압축률, 매우 빠른 읽기 및 쓰기 속도