R에서 카카오 검색 API 사용하기
예제 · 케이플러스 한성탁 ·다른 포스트(링크) 에서 네이버 검색 API를 R을 통해 사용해봤습니다. 이번엔 카카오 API를 써 보겠습니다.
카카오 API 출시 시에는 검색 API가 포함되지 않았는데 이번에 새로 나왔습니다. 대신 다음 API에서 기존 사용자는 API를 계속 사용가능하나 신규 사용자를 막았습니다. 개발자 페이지에서도 다음 -> 카카오로 변경하려는 움직임이 있는 듯 합니다.
- 카카오 API 생성하기
먼저 카카오 아이디가 없으신분은 카카오 아이디를 만드시기 바랍니다.
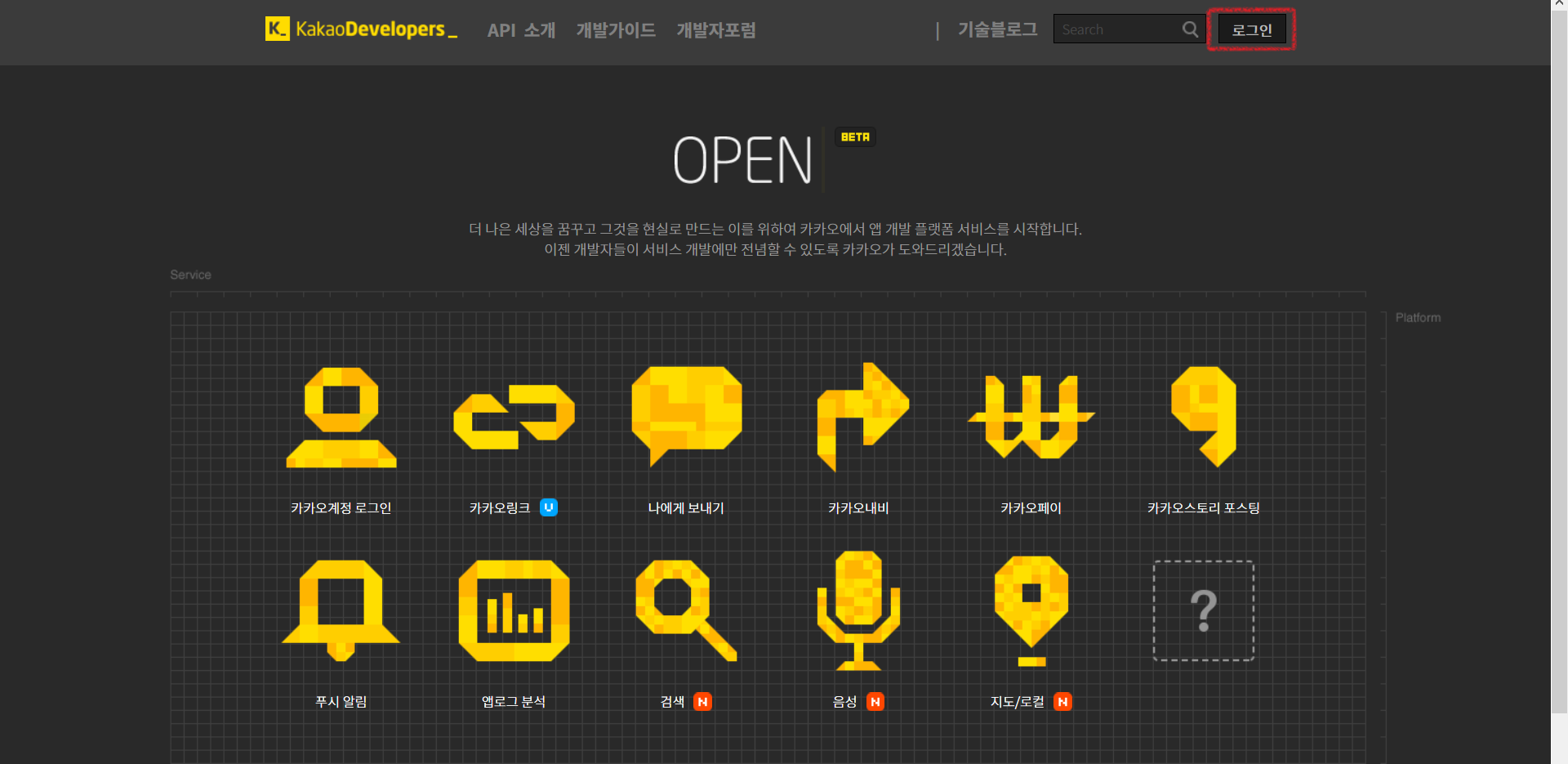
카카오 개발자 페이지(링크)에 들어갑니다. 로그인 버튼을 클릭하면 자동으로 개발자 등록 화면으로 넘어갑니다.
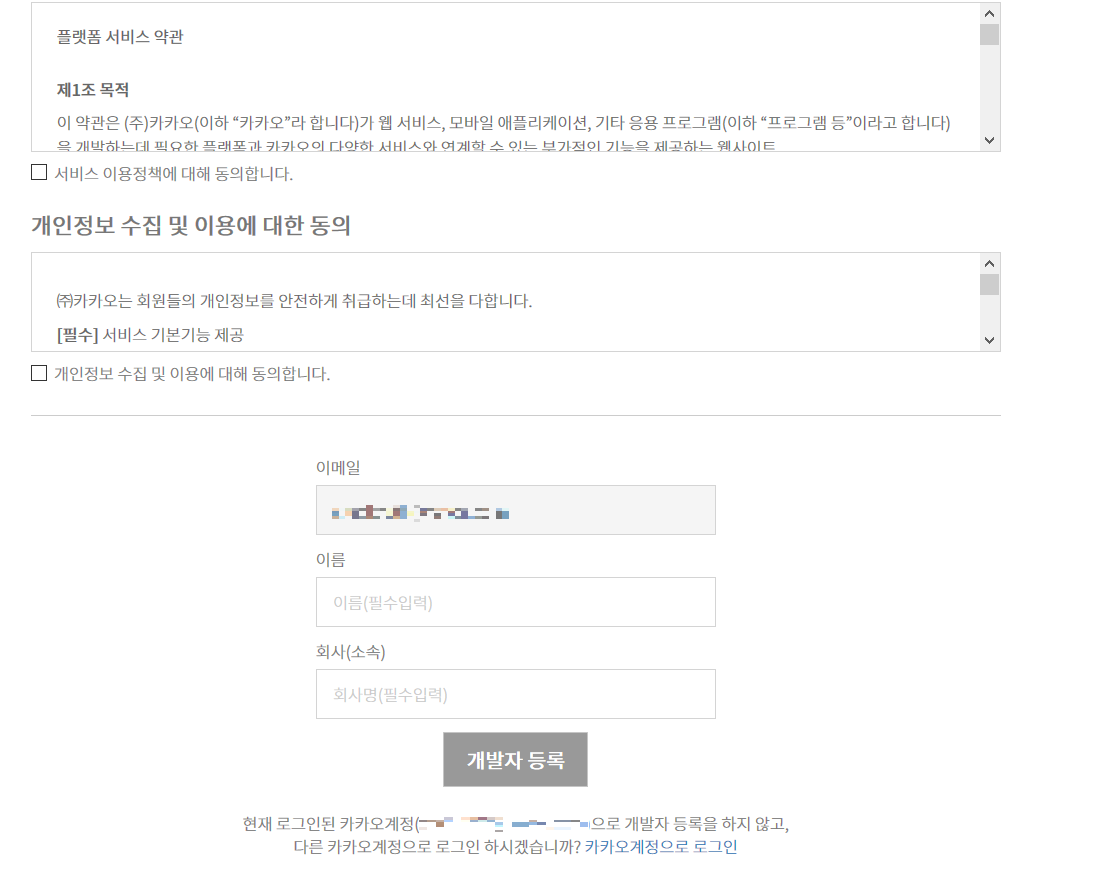
이름, 소속 등을 입력한 후 API 이용 약관에 동의한 후 다음으로 넘어갑니다. 다시 말씀드리지만 이용 약관은 꼭 읽어보시기를 추천합니다. 개인적인 테스트나 연구 목적이면 대체로 상관 없으나 API 내용을 상업적으로 이용하거나 공모전 등에 이용할 경우 문제의 소지가 있으므로 약관을 숙지하시기 바랍니다.
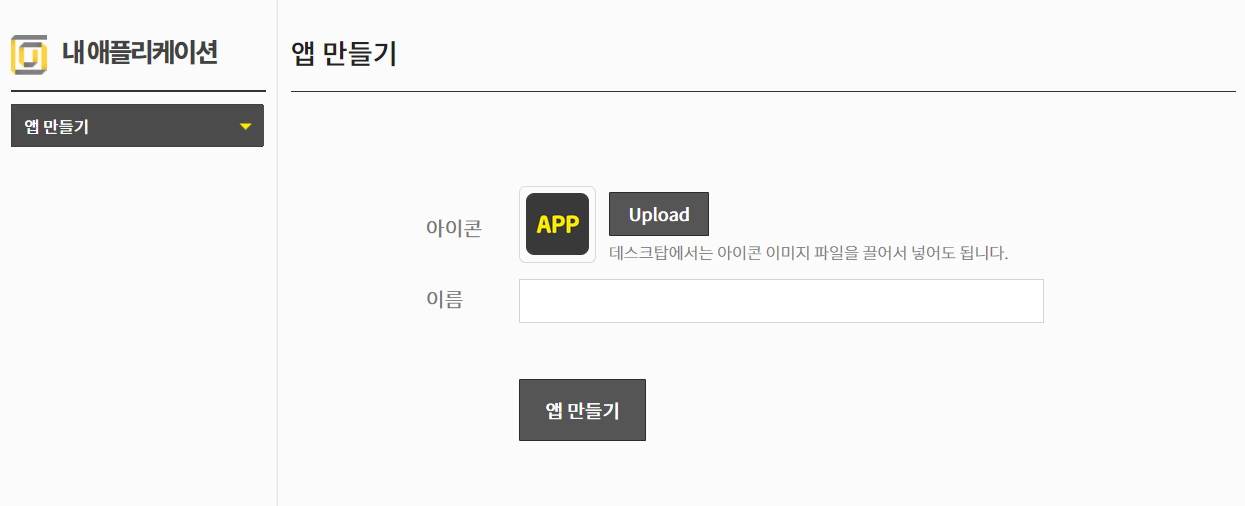
앱 만들기 화면에서 앱의 아이콘과 이름을 정합니다. 적당히 정해주시면 됩니다.
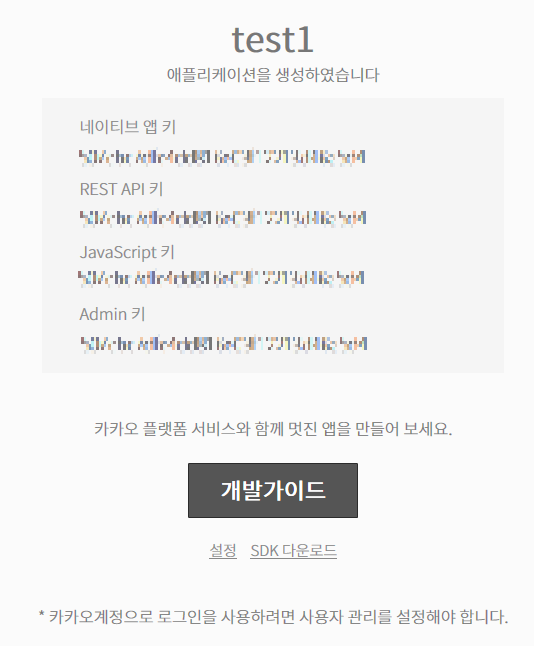
앱이 생성되면 자동으로 키를 발급해줍니다. 여기서 REST API키를 사용하게 됩니다. API 키는 언제든지 확인 가능하지만 외부에 노출되지 않도록 하시기 바랍니다. 개인적으로는 발급 과정이 네이버보다 간편하다고 느꼈습니다.
- 카카오 검색 API
코드를 작성하기 전에 카카오 개발자 페이지에서 검색 API에 대한 내용을 좀 살펴보겠습니다.
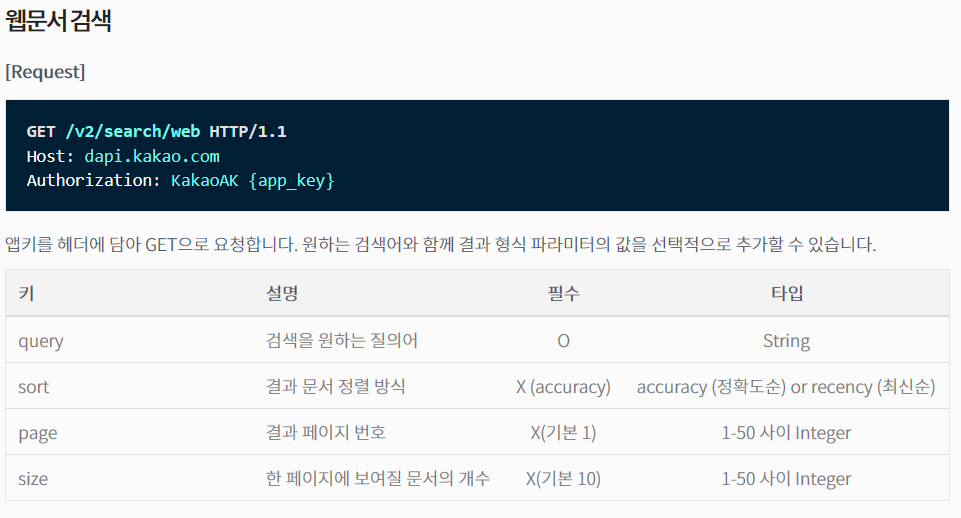
웹 문서 검색 API의 설명을 보면
- 호출은 GET 프로토콜
- API 주소는 https://dapi.kakao.com/v2/search/web
- 인증은 API 키
- 검색 인수는 query, sort, page, size
등의 사실을 알 수 있습니다. 아래쪽의 출력 결과를 보면
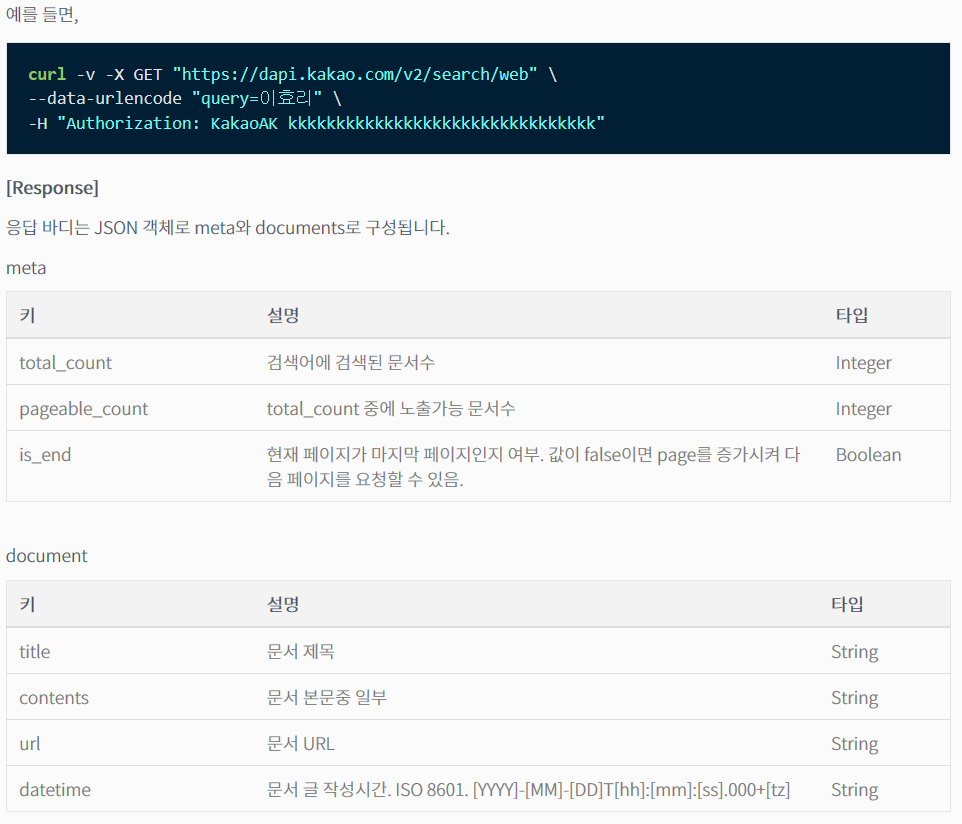
- 응답 파일 형식은 JSON
- 응답되는 내용은 문서 수, 문서 제목, 문서 본문 일부, URL, 문서 작성 시간 등
XML 형식을 선택할 수 없다는 것을 제외하면 네이버 API와 거의 동일합니다. 사실은 다음 API와도 동일합니다. API 주소에서 dapi가 daum api의 약자가 아닌가 하는 우려가 생기네요.
- R에서 카카오 API 호출하기
바로 R에서 카카오 API를 호출할 설정을 하겠습니다.
api_url = "https://dapi.kakao.com/v2/search/web"
우선 api의 url을 지정합니다. 위의 경우는 ‘웹문서’에 대한 검색결과를 JSON 포맷으로 반환받게 됩니다.
- 이미지 : https://dapi.kakao.com/v2/search/image
- 블로그 : https://dapi.kakao.com/v2/search/blog
- 카페 : https://dapi.kakao.com/v2/search/cafe
각 분야마다 검색 API로 검색이 가능하며, 사용되는 인수가 조금씩 다르므로 카카오 개발자 페이지에서 확인해가면써 사용하시기 바랍니다.
query = URLencode(iconv("안드로이드", to="UTF-8"))
query = str_c("?query=", query)
카카오 API도 네이버와 마찬가지로 검색어를 URLencode()를 이용하여 URL 인코딩 형식으로 변환하고, 필요한 부분을 붙여줍니다.
result = GET(str_c(api_url, query),
add_headers("Authorization" = str_c("KakaoAK ", api_key)))
앞에서 얻은 api_key를 입력하고, GET()을 실행하면 json 포맷의 결과 데이터를 얻을 수 있습니다. OAuth 2.0 을 사용하던 다음 API 때 보다 인증이 쉬워졌습니다.
카카오 API도 GET 프로토콜을 사용하지만 보안 문제인지 API 키는 헤더에서 전송합니다.
con = content(result)
R에는 JSON 형식을 읽는 패키지가 있지만, content() 함수를 이용하면 다른 패키지 필요 없이 계층 구조로 된 결과데이터를 얻을 수 있습니다.
con$meta$dup_count
con$meta$pageable_count
con$meta$total_count
con$meta$is_end
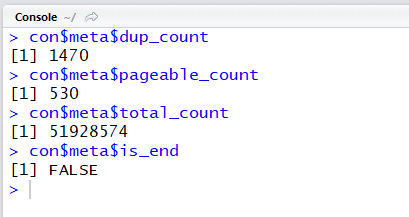
중복 문서 수, 페이지 가능 수, 총 문서 수
sapply(con$documents, function(x) x$title)
sapply(con$documents, function(x) x$contents)
sapply(con$documents, function(x) x$url)
sapply(con$documents, function(x) x$datetime)
sapply()를 이용하면 결과를 한 눈에 볼 수 있습니다.
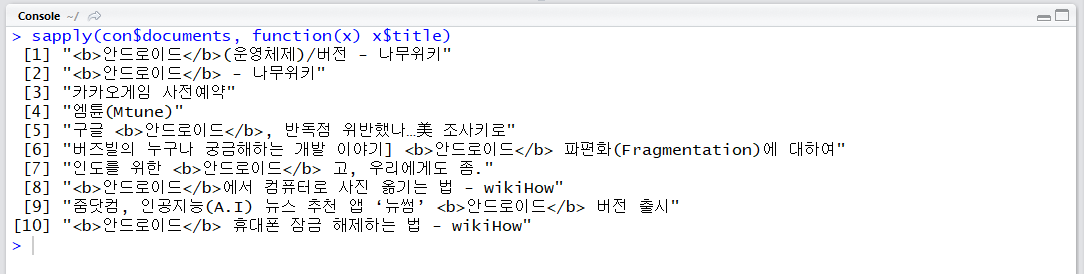

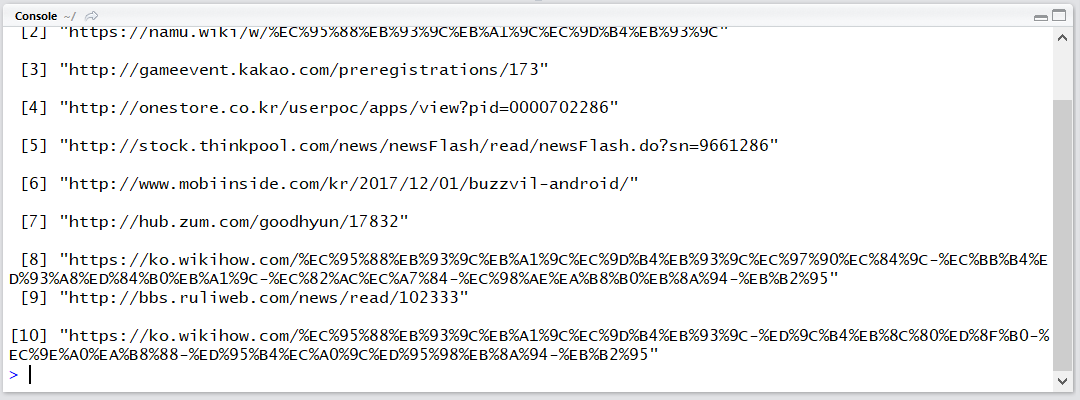

마지막 datetime의 경우 앞 부분이 협정 세계시(UTC, GMT) 뒷 부분이 우리나라에 대한 조정 (+9시간)입니다. 웹 문서는 데이터 특성 상 시간이 정확하지 않을 수도 있습니다.
검색 결과에 대해 웹 문서의 제목, 주소, 내용의 일부를 얻을 수 있었습니다. 이제 API에서 query인수 외의 sort, page, size 등의 인수를 조절하면서 자동화하면 지정된 키워드에 대해 정보를 탐색할 수 있습니다.
검색 결과 표시 개수 조정
size_ = "&size=50"
result = GET(str_c(api_url, query, size_),
add_headers("Authorization" = str_c("KakaoAK ", api_key)))
con = content(result)
sapply(con$documents, function(x) x$title)

검색 결과 출력 시작 위치 조정
page_ = "&page=2"
result = GET(str_c(api_url, query, page_),
add_headers("Authorization" = str_c("KakaoAK ", api_key)))
con = content(result)
sapply(con$documents, function(x) x$title)

검색 결과 정렬 기준을 날짜순으로
sort_ = "&sort=recency"
result = GET(str_c(api_url, query, sort_),
add_headers("Authorization" = str_c("KakaoAK ", api_key)))
con = content(result)
sapply(con$documents, function(x) x$title)
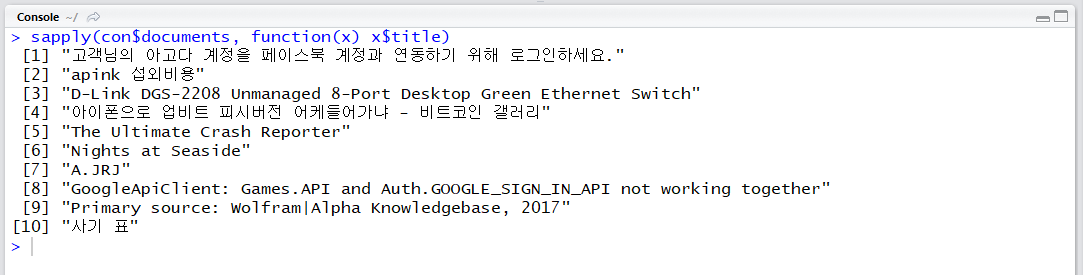
카카오 API는 웹 문서 검색에서도 날짜순 정렬이 작동합니다.
위의 결과 전부 적용
result = GET(str_c(api_url, query, size_, page_, sort_),
add_headers("Authorization" = str_c("KakaoAK ", api_key)))
con = content(result)
sapply(con$documents, function(x) x$title)
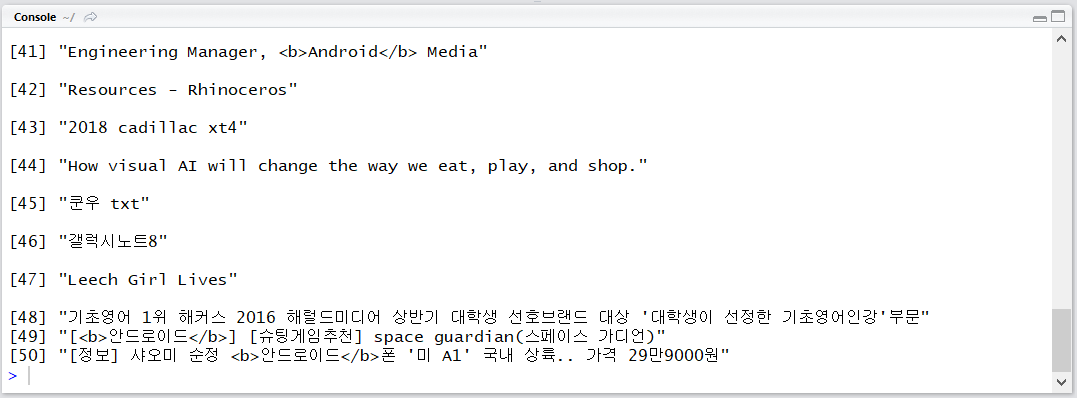
네이버는 최대 1099개의 결과를 얻을 수 있었는데 카카오 API는 50*50=2500개의 검색 결과를 얻을 수 있으므로 검색 데이터 개수에서는 약간 우위를 가집니다. 검색 기간 조절은 여전히 불가능합니다.
아래는 전체 코드입니다.
require(httr)
require(stringr)
require(XML)
require(rjson)
api_url = "https://dapi.kakao.com/v2/search/web"
query = URLencode(iconv("안드로이드", to="UTF-8"))
query = str_c("?query=", query)
api_key = ""
result = GET(str_c(api_url, query),
add_headers("Authorization" = str_c("KakaoAK ", api_key)))
con = content(result)
con$meta$dup_count
con$meta$pageable_count
con$meta$total_count
con$meta$is_end
sapply(con$documents, function(x) x$title)
sapply(con$documents, function(x) x$contents)
sapply(con$documents, function(x) x$url)
sapply(con$documents, function(x) x$datetime)
# 검색 결과를 50건 출력 (한 페이지 최대 50건)
size_ = "&size=50"
result = GET(str_c(api_url, query, size_),
add_headers("Authorization" = str_c("KakaoAK ", api_key)))
con = content(result)
sapply(con$documents, function(x) x$title)
# 2번째 페이지 출력 (최대 50페이지)
page_ = "&page=2"
result = GET(str_c(api_url, query, page_),
add_headers("Authorization" = str_c("KakaoAK ", api_key)))
con = content(result)
sapply(con$documents, function(x) x$title)
# 유사도가 아닌 날짜순으로 검색된 결과 출력
sort_ = "&sort=recency"
result = GET(str_c(api_url, query, sort_),
add_headers("Authorization" = str_c("KakaoAK ", api_key)))
con = content(result)
sapply(con$documents, function(x) x$title)
# 위의 결과 전부 적용
result = GET(str_c(api_url, query, size_, page_, sort_),
add_headers("Authorization" = str_c("KakaoAK ", api_key)))
con = content(result)
sapply(con$documents, function(x) x$title)